八股系列|操作系统|内存管理篇一

文章目录
内存管理
为什么要有虚拟内存?
设想以下:如果我们在指定物理地址的内存上装载两个及以上的应用程序。这两个程序事先并没有协商,那么很容易出现一个程序占用了另一个程序的内存空间或者此时放入一个新的值到一个程序的内存空间,这都是非常危险的。
所以,我们需要让进程使用的物理内存相互隔离起来,即让操作系统为每个进程独立分配一套虚拟地址,使得彼此互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。而且,每个进程的虚拟地址范围都是一样的,但是映射于不同的物理地址。
操作系统会提供一种机制,把不同进程的虚拟地址与不同内存的物理地址映射起来
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
虚拟内存地址是怎么转化为物理内存地址的?
进程持有的虚拟地址会借助CPU芯片里的内存管理单元(MMU)转化为物理地址,然后根据物理地址访问物理内存。
分段机制下,虚拟地址和物理地址是如何映射的?
分段方式是早期提出的非连续内存分配方式。分段的意思就是将进程所需的内存一次性分配出去,要多少,就分配多少。
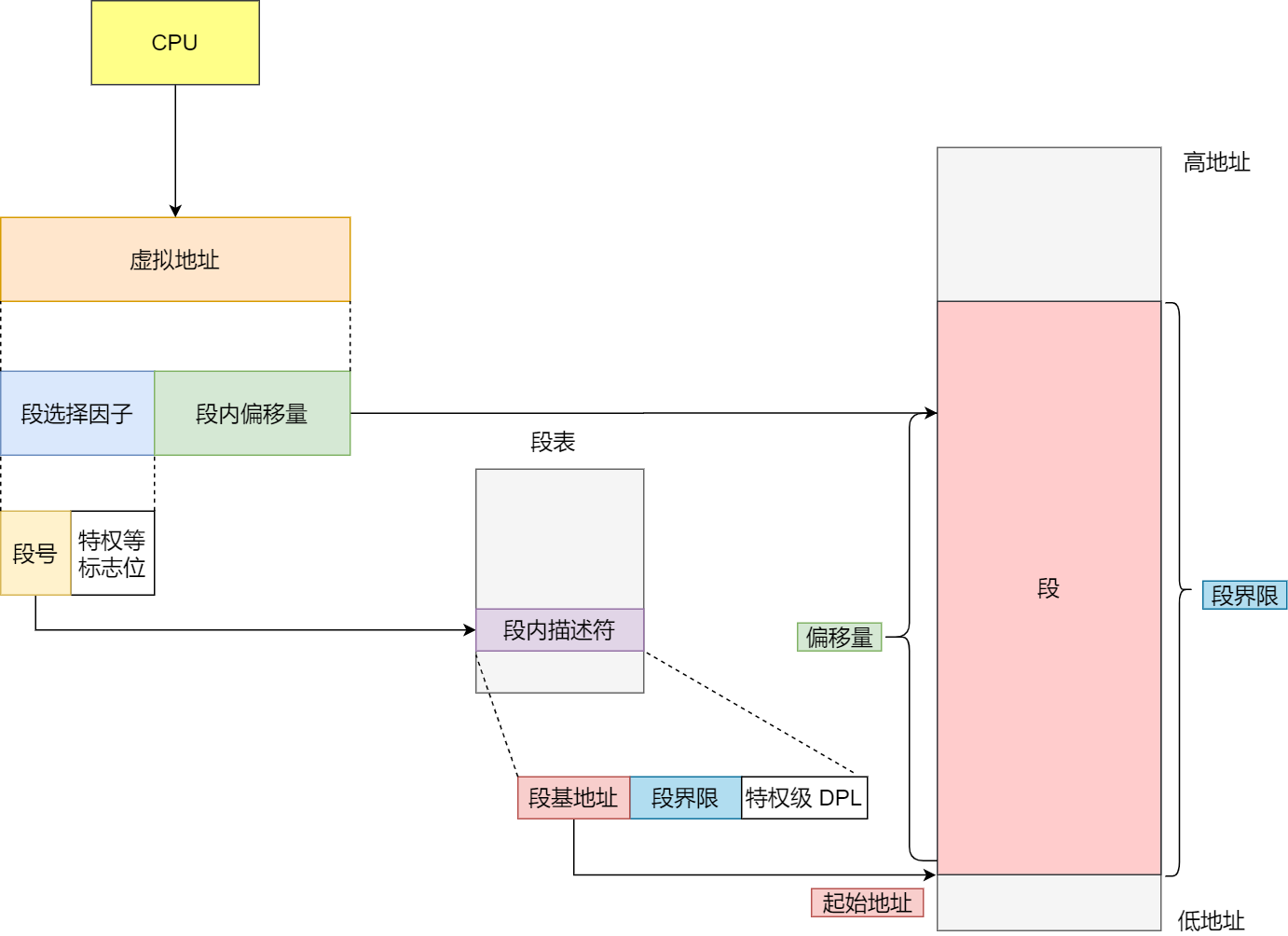
段选择因子和段内偏移量:
- 段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
在上面,知道了虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,
分段为什么会产生内存碎片的问题?
这种分配方式很明显,不会有内存的内部碎片,但是会有外部碎片。因为分段方式是一次性分配连续空间,假如:进程A、B装载到内存里,两者中间刚好只有4M的空间,此时又装载20M的进程C,显然,A和B之间放不下,出现间隙,也就是外部碎片。
分段为什么会导致内存交换效率低的问题?
除了外部碎片的问题,分段方式由于是一次性连续分配进程所需内存空间,可能分配的比较大,那么后续内存占满了再有进程装载内存时,会发生内存交换,与磁盘交换一个容量较大的进程,显然,也会变慢,也就是内存交换效率变低
但是分段也有好处,分段会产生连续的内存空间。
分页机制下,虚拟地址和物理地址如何映射?
分页方式的出现解决了分段方式带来的内存外部碎片和内存交换效率慢的问题。其实归根结底,分段方式为什么会带来内存外部碎片?主要原因还是按照分段方式分配的内存空间,视进程而定,有些需要较大内存的进程会申请较大的连续的内存空间。这就会导致外部碎片和内存交换效率低下。
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址,见下图。
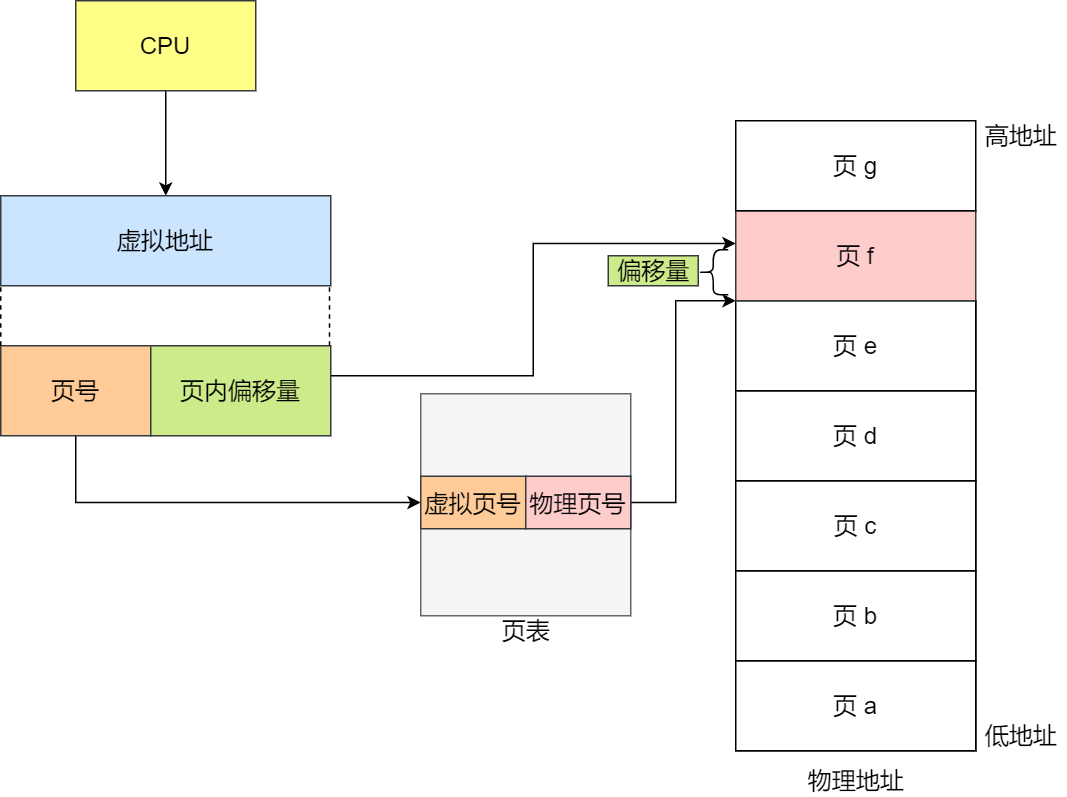
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
分页是怎么解决分段的「外部内存碎片和内存交换效率低」的问题?
我们减小分段分配的内存大小,预先把内存划分为小的连续排布的块(页)。进程要多少内存,我们分配N个固定大小的页,也就是分页。我们分配的是紧凑排布的页,不会出现外部碎片的问题,但是有可能最后一个分配的页没有使用完,会导致内部碎片。而发生内存交换时,也是以页为单位进行交换,页相对段来说更小,所以内存交换效率也更高。
而且,分页方式的使得我们装载程序,不用一次性将整个程序都装载到内存里。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
简单的分页有什么缺陷?如何解决?
因为分页的单位页通常来说很小,需要的页表也会变大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有
4MB的内存来存储页表。而操作系统会运行数百以上的进程,光是存储页表就需要4MB*数百。内存开销大.
在前面我们知道了,对于单页表的实现方式,在 32 位和页大小 4KB 的环境下,一个进程的页表需要装下 100 多万个「页表项」,并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
采用多级分页的方式:
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。如下图所示:
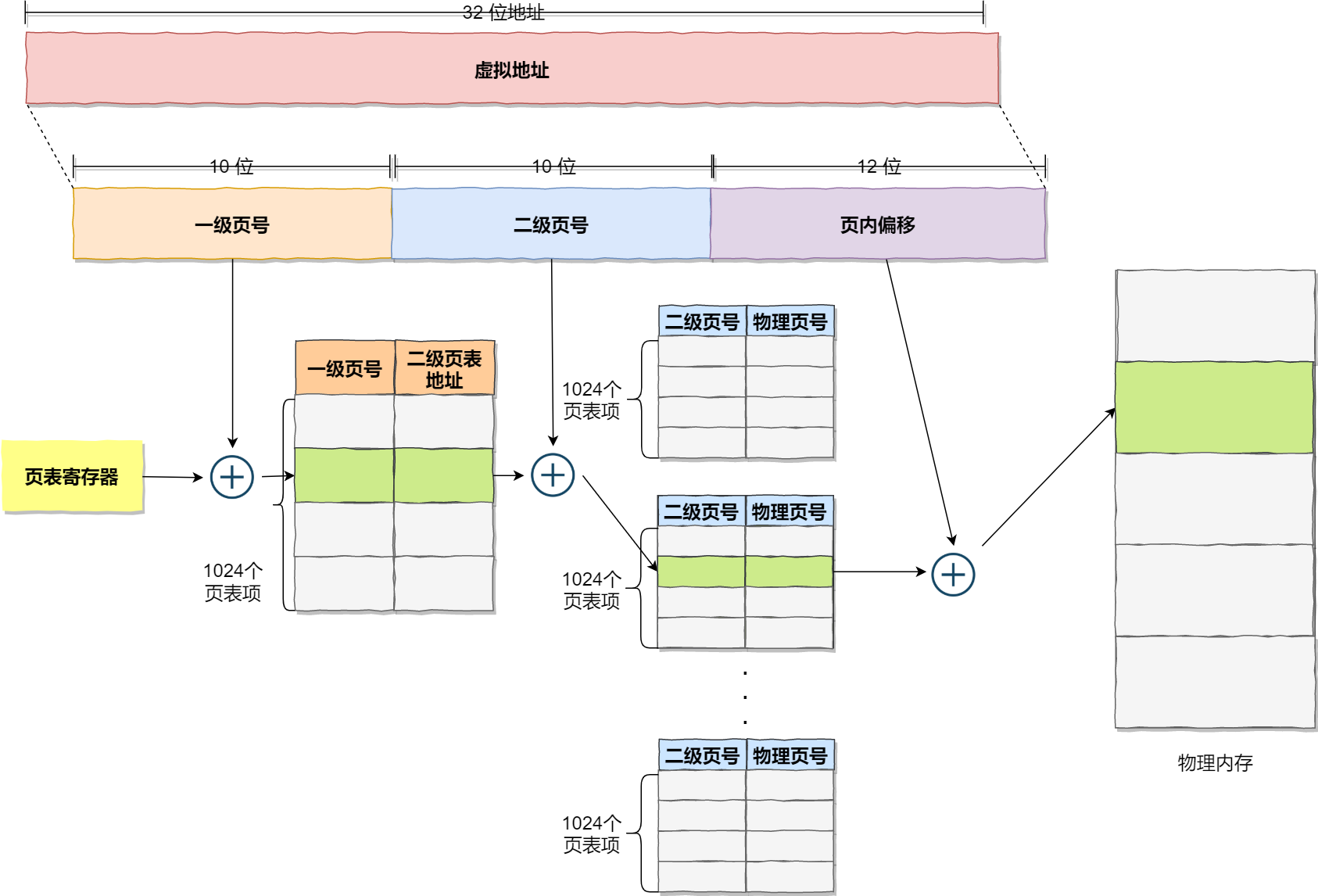
页表项大小:4bytes
从上面的图看出:页表有两个(一级页表和二级页表)。一级页表索引二级页表,二级页表索引物理页号。其中一级页表(只有一个)大小4KB=1024*4B,二级页表总大小4mB=1024*1024*4B,那么总大小是4KB+4MB>4MB.
好像二级分页变得更大了?
其实不然,如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。
多级分页带来了繁杂的地址转换,TLB来优化
程序是有局部性的,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
我们就可以利用这一特性,把最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
虚拟内存有什么作用?
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
内存分配过程是怎样的?
-
如果内存充足情况下,不需要触发内存回收,足够给新的进程分配新的内存空间;
-
如果此时内存有一定压力,但是还是可以继续分配出足够空间给进程(页低阈值page_low<剩余内存<页高阈值page_high);
-
如果内存此时压力太大,剩余内存不多,不足以继续分配出足够地内存(页高阈值page_high<剩余内存<页最小阈值(page_min)),那么会触发后台内存回收的内核线程去异步非阻塞地回收内存(匿名页和文件页);
-
如果此时剩余内存几乎耗尽(剩余内存<页最小阈值(page_min)),那么会触发直接内存回收,同步阻塞地回收内存。此时,系统无法为新的进程分配内存空间,从外面看上去系统很卡顿。
-
如果直接内存回收无法满足内存需求,那么就会触发OOM(out of memory)机制:
内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
OOM发生后,会根据算法选择一个占用物理内存较高地进程,将其杀死并回收其内存资源,如果还不够,再循环这个过程。OOM是一个隐藏的性能杀手,我们应该尽量避免发生OOM后,系统杀死一些关键进程,如我们的关键业务进程,系统基础服务进程等。
哪些内存可以被回收?
不是所有的内存都可以回收,有些内存磁盘里没有直接回收会造成数据丢失的问题。我们可以采取LRU算法策略回收文件页和匿名页。
-
文件页
文件页是操作系统用来缓存文件数据的内存页,位于page cache里,使得读写磁盘的时候,不直接与磁盘交互,从而提升读写性能。所以,这部分数据在物理磁盘上使用存储的,我们直接将它回收,如果要再次使用再加载进来即可。当然,回收干净页可以直接回收,但是脏页需要先写入磁盘(fsync调用)才能被回收。
-
匿名页
这部分数据和文件页不一样,没有预先持久化,丢掉就没有了。所以,在被回收之前,需要先持久化到磁盘里(也就是换出),然后再被回收,需要的时候再加载到内存(换入)。
LRU指的是回收近期最不常访问的内存
内存回收会带来哪些性能影响?以及如何改善?
-
内存回收的方式有两种,后台内存回收对性能影响甚微,但是可以缓解我们的内存剩余紧张问题,所以,我们应该尽早进行后台内存回收,上调后台内存回收的阈值,尽早触发后台内存回收;
-
还有就是直接内存回收,会同步阻塞地执行,会阻塞后续进程的内存申请,CPU利用率会升高
-
回收干净的文件页不会触发磁盘IO,但是回收脏页可能会触发两次磁盘IO,回收匿名页也可能触发两次IO。
其中脏页触发第二次磁盘IO的概率小点,而匿名页很可能会再次被使用,触发第二次可能性更高。所以综合来看,回收文件页要比回收匿名页划算一些。
除了OOM,内存满了还会发生什么?
OOM发生,会去kill内存占用较大的进程,以此释放内存空间。除了内存满了,会触发kill以外,还会发生:
- 某些进程崩溃或无法创建新的进程:因为此时内存满了,无法再给进程或新的进程分配所需内存空间,导致进程崩溃或无法建立
- 系统变得异常缓慢或无响应:系统无法给新的进程或线程分配所需的内存资源,所以无法正常响应用户的请求。
如何保护一个进程不被OOM?
调整OOM机制算法的参数oom_score_adj,使得进程被OOM kill掉的几率变低。
在4GB物理内存的机器上,申请8GB内存会怎么样?
- 如果是32位系统,进程理论上能申请最大3GB的虚拟内存(总共4GB,内核空间占了1GB),显然8GB>3GB,无法申请成功
- 而64位系统,进程理论上能申请最大128TB的虚拟内存,即时只有4GB物理内存。因为申请了这么多虚拟内存,不一定都使用对应的物理内存。
- 如果没有开启swap,且物理内存不够,就会触发OOM,杀死进程,不能分配8GB内存
- 如果开起swap,就算物理内存不够,还可以通过swap来不断换入换出,让4GB物理内存可以运行8GB内存需求的应用。
如何改进LRU以避免或减轻缓存污染和预读失效的问题?
我们知道传统LRU就是:LRU算法使用数据结构链表来实现,表头是最近被访问的数据,表尾是最久之前被访问的数据。每当数据被访问,就将数据移到表头;当内存容量满了,就从表尾把数据换出到磁盘或者删除。
-
缓存污染
由于数据被访问就会移到表头,可能会造成这样一种情况:近期对大量非热点数据进行访问,导致近期热点数据移至链表尾部甚至被淘汰,然而这些非热点数据后续访问热度低下,从而对缓存造成了污染
-
预读失效
一个操作系统page cache的预读机制:系统读写文件数据,没有在page cache里找到数据,根据空间局部性原理,除了会从磁盘里加载数据所在的页到page cache里,还会加载相邻的几个页也到page cache里。然而如果这些预读的页没有被访问,那么就是预读失效,而且还会把热点数据挤出去。
如何解决缓存污染问题?
lru会出现缓存污染问题的根本原因在于“只要数据被访问一次,就将数据移到链表首部”。仅仅访问一次,并不能代表这就是热点数据,有可能只是偶尔突发性地访问了大量数据,但是后续没有访问,这样会把一些热点数据挤出去。所以,参考lru-k算法,我们提交真正移到lru链表首部的条件,例如访问两次过后,我们认为这确实是一个热点数据,将这个热点数据放到活跃lru链表里。
Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
如何解决预读失效问题?
预读失效的原因在于空间局部性原理,但是空间局部性原理在大部分情况下依然是有效的。
我们让真正被访问的页才移动到lru链表头部,这样就能保证真正被访问的数据可以在内存里驻留更长的时间,防止被预读页挤出去。预读页有可能会被访问到,没访问之前,我们放在另一个不活跃lru链表;被访问之后,我们在将其移到活跃lru链表首部。这正是linux系统page cache缓存淘汰策略lru的改进。这个有点类似于2Q算法的思想:冷热分离。
文章作者 cold-bin
上次更新 2023-08-23