八股系列|操作系统|硬件结构

文章目录
这里记录一些不是很体系化,但是偶尔乍现的问题与其解
操作系统之硬件结构
CPU是如何执行程序的?
CPU是计算机的核心部件,包含控制器、运算器和寄存器等部件。CPU是通过“取指执行”过程来执行程序的。我们编写的高级语言程序,最终会被解释成CPU看得懂的指令。然后CPU执行以下过程来执行指令:
- 取出指令:CPU根据程序计数器(PC)中存储的地址,将指令从主存(内存)读到指令寄存器(IR)中,然后PC指向下一个指令;
- 指令译码:按照预定的指令格式对指令进行译码,识别出不同指令的格式以及获取操作数的方式;
- 执行指令:CPU按照指令译码得到的控制信号进行操作,期间可能会发生主存(内存)访问;
- 访存取数:CPU根据指令的需要,有可能会访问内存,读取操作数。不同指令可能会采用不同的内存访问方式(立即寻址、直接寻找,间接寻址,寄存器寻址等)得到主存地址,然后根据地址取出操作数;
- 结果写回:CPU执行完当前指令后,会把结果写入寄存器、主存或其他位置。
- 然后又可以回到步骤1,循环执行;
当然,指令执行并非一番风顺,可能会发生无法执行的指令,CPU会中断现场,从而让中断程序来处理。
例如:a = 2÷0这段程序,CPU无法执行,会发生中断报除0错误。
磁盘比内存快几万倍?
磁盘是机械结构,读写数据需要物理移动磁头,而内存读写是刷新DRAM里的电信号,两者相比内存要比磁盘块好几个数量级。
下面是计算机系统存储系统组成图:
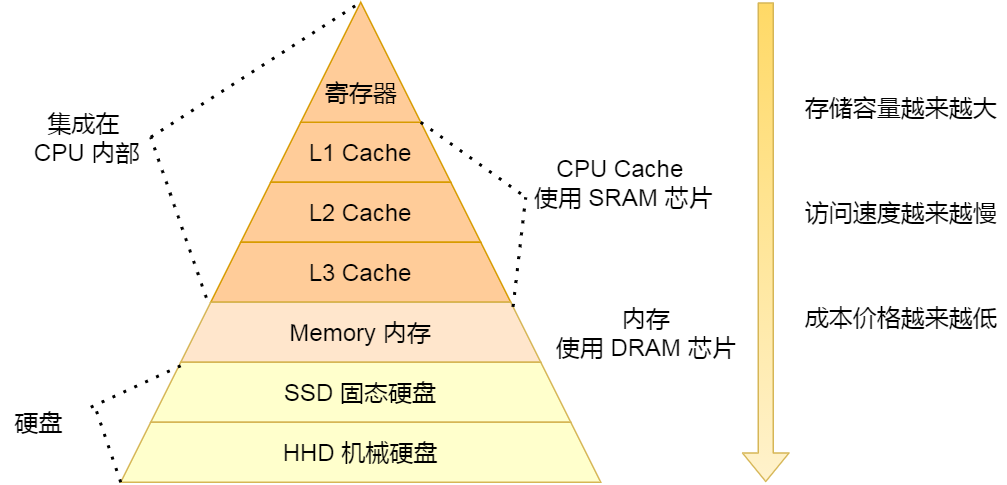
从上到下的存储器构成了一个类似于多级缓存体系的结构,CPU先读速度与CPU最匹配的寄存器,没有就去读速度稍慢的L1级cache;还没有再去读速度更慢的L2、L3级cache;再没有去读速度更更慢内存,还没有就读速度最慢的磁盘
- 寄存器:属于CPU部件,寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写
- cache:使用SRAM芯片构成,只要有电就有数据,断电会丢失数据。每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存(哈弗结构)。
- 主存(内存):使用DRAM芯片构成。相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。DRAM是通过电容带电来保存数据,所以需要不断的充放电,也就是刷新,来保证DRAM数据不丢失。和SRAM一样,断电会丢失数据,一直充电才能保存数据
- SSD/HHD:数据保存在物理上,断电后依然存在,可以作为持久化存储的介质
如何写出让CPU跑得快的代码?
如何才能让我们的代码跑得更快呢?应该从四方面考虑:
-
如何提升数据的cache命中率?
举个例子:我们
先遍历第一行,再遍历第二行和先遍历第一列,再遍历第二列哪个更快?因为二维数组是按照行来存储的。所以,我们
先遍历第一行,再遍历第二行的方式其实就是顺序读取,一次读取cache会把相邻的数据也加载到cache,而相邻cache的数据有极大概率是数组的下一个数据;而先遍历第一列,再遍历第二列并不是顺序读取,假设读取数组第一行第一列的数据,cache加载第一行的数据进来,刚好cache满了,此时再读第二行第一列的数据,cache里没有,只能再去内存里加载进来第二行,如此循环往复,cache的命中率显然低于前者。(CPU的局部性原理)总结:提升数据的缓存命中率的方式,是按照内存布局顺序访问
-
简单来说,就是在if判断之前,就预测接下来执行哪个分支的指令,从而把这些提前缓存下来,提高cache的命中率。
-
如何提升多核CPU的cache命中率?
每个CPU内核都有自己的L1、L2级cache和共同的L3级cache。如果一个线程在不同核心之间切换,可能会降低cache的命中率,因此我们可以把线程绑定到某个特定的核心上执行,从而提高cache命中率。
-
如何使用到使用多核CPU的优势?
单核CPU并不能做到并行,多核CPU可以做到并发+并行。我们可以将多个线程绑定到多个内核执行。也就是使用并发编程。
怎样保证cache和主存的缓存一致性的?
CPU 在读写数据的时候,都是在 CPU Cache 读写数据的,原因是 Cache 离 CPU 很近,读写性能相比内存高出很多。对于 Cache 里没有缓存 CPU 所需要读取的数据的这种情况,CPU 则会从内存读取数据,并将数据缓存到 Cache 里面,最后 CPU 再从 Cache 读取数据。
而对于数据的写入,CPU 都会先写入到 Cache 里面,然后再在找个合适的时机写入到内存,那就有「写直达」和「写回」这两种策略来保证 Cache 与内存的数据一致性:
- 写直达,只要有数据写入,都会直接把数据写入到内存里面,这种方式简单直观,但是性能就会受限于内存的访问速度;
- 写回,对于已经缓存在 Cache 的数据的写入,只需要更新其数据就可以,不用写入到内存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到内存里,这种方式在缓存命中率高的情况,性能会更好;
如何保证多级cache的缓存一致性?
当今 CPU 都是多核的,每个核心都有各自独立的 L1/L2 Cache,只有 L3 Cache 是多个核心之间共享的。所以,我们要确保多核缓存是一致性的,否则会出现错误的结果。
要想实现缓存一致性,关键是要满足 2 点:
- 第一点是写传播,也就是当某个 CPU 核心发生写入操作时,需要把该事件广播通知给其他核心;
- 第二点是事物的串行化,这个很重要,只有保证了这个,才能保障我们的数据是真正一致的,我们的程序在各个不同的核心上运行的结果也是一致的;
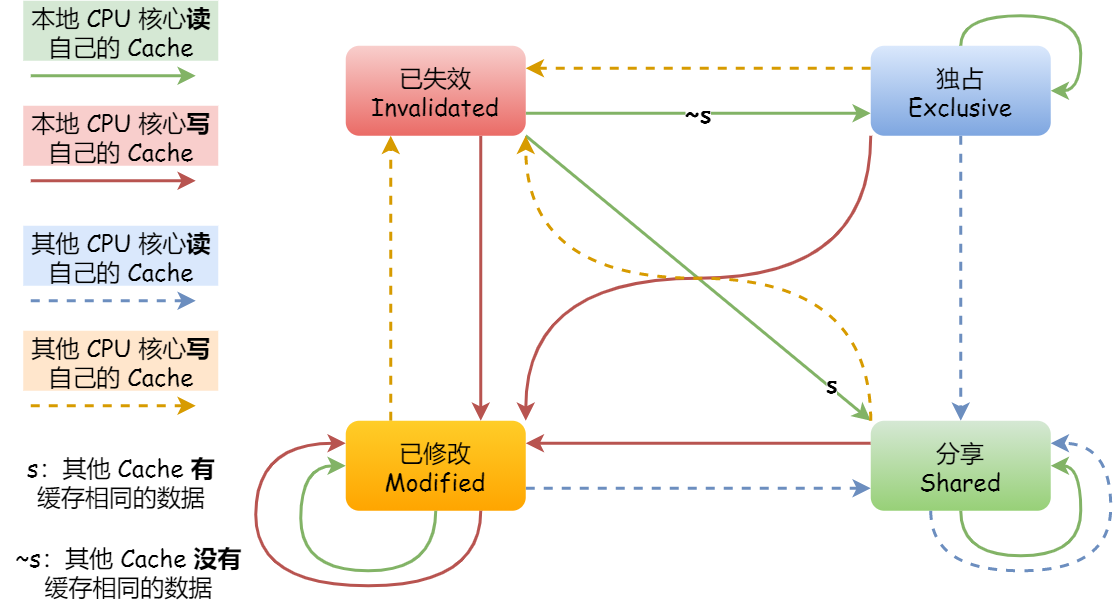
基于总线嗅探机制的 MESI 协议,就满足上面了这两点,因此它是保障缓存一致性的协议。
MESI 协议,是已修改、独占、共享、已失效这四个状态的英文缩写的组合。整个 MSI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心。
为什么 CPU 里会有 L1~L3 Cache ?
cache的访问速度比内存快的多,CPU先访问cache,cache没命中再从内存里调入块到cache中,这样可以避免直接访问速度更慢的内存,加快了访问速度。
说一下CPU的局部性原理
- 空间局部性原理:相邻存储的数据或指令,很有可能会被再次使用
- 时间局部性原理:近期使用的数据或指令,很有可能会被再次使用
我们利用局部性原理,我们加载数据的时候,无论是从磁盘到内存,还是内存到磁盘,都不仅仅只是加载一个字,而是一个块(64字节)。
说一下cache的伪共享问题
cache的伪共享指的就是如果并发地更改同一个cache块的两个变量,cache本身就没有起作用,还需要从主存再次加载cache进来。
现代CPU架构中多核且含多级cache,其中L1 cache和L2 cache每个核独有,L3 cache共享
但是,CPU修改数据并不是直接修改主存,一定是修改L1 cache中的数据,如果没有会去后面的cache去调,还没有再从主存里调块过来。因此,为了避免伪共享问题发生,我们空间换时间:
可能发生并发读写同一个结构体里多个变量(地址虽然不一定连续,但是可能都在一个cache块)这种情况,我们就在每个可能并发修改的变量中间加个padding(cache block size),让这并发修改的两个变量位于两个不同的cache块。这样就避免了伪共享问题发生
线程为什么叫轻量级进程呢?
在 Linux 内核中,进程和线程都是用 task_struct 结构体表示的,区别在于线程的 task_struct 结构体里部分资源是共享了进程已创建的资源,比如内存地址空间、代码段、文件描述符等,所以 Linux 中的线程也被称为轻量级进程,因为线程的task_struct相比进程的 task_struct 承载的 资源比较少,因此以「轻」得名。
中断是什么?
中断就是CPU接收来自硬件或软件的中断信号后,会中断当前程序的执行,转而去执行中断服务程序。中断处理程序在响应中断时,可能还会「临时关闭中断」,这意味着,如果当前中断处理程序没有执行完之前,系统中其他的中断请求都无法被响应,也就说中断有可能会丢失,所以中断处理程序要短且快。
什么是软中断和硬中断?什么是软件中断?
-
硬中断
由与系统相连的硬件(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。
-
软中断
为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到后面来完成,也就是软中断(softirq)来完成。
软中断由内核触发中断,异步处理上半部分剩下的工作
所以,linux中断服务程序分为上半部(硬中断)和下半部(软中断)
-
软中断指令
int是软中断指令。中断向量表是中断号和中断处理函数地址的对应表。
int n– 触发软中断n。相应的中断处理函数的地址为:中断向量表地址 + 4 * n。 -
软中断和硬中断区别
- 软中断是执行中断指令产生的,而硬中断是由外设引发的。
- 硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。
- 硬中断是可屏蔽的,软中断不可屏蔽。
- 硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。
- 软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。
为什么负数要用补码表示?而不用原码或反码?
-
原码就是数据二进制和最高位的符号位表示。最高位:0表示正数,1表示负数;
原码就是原始数据。
-
反码就是原码基础上所有数据位取反,符号位不变。
反码就相当于数学里的负数,使得
2-1=2+(-1),把减法转化为加法,统一了加减法,让硬件电路设计更加简单。 -
补码就是在反码基础上+1
反码中
0的表示有-0和+0两个不同的编码,但是代表同一个值。对于计算机来说很不好区分。所以采用补码的方式将0的表示统一
因此,计算机中负数采用补码表示,可以降低硬件电路设计复杂度和消除0的编码不唯一性。
计算机如何存储小数?
现在绝大多数计算机使用的浮点数,一般采用的是 IEEE 制定的国际标准,这种标准形式如下图:

这三个重要部分的意义如下:
- 符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
- 指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表达范围就越大;
- 尾数位:小数点右侧的数字,也就是小数部分,比如二进制 1.0011 x 2^(-2),尾数部分就是 0011,而且尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
对于我们在从 float 的二进制浮点数转换成十进制时,要考虑到这个隐含的 1,转换公式如下:

0.1 + 0.2 == 0.3 吗?
答案是不等。为什么呢?那就要看浮点数是如何存储在计算机中的了:0.1是十进制表示,转化为二进制时,是一串无限循环二进制数,那么在IEEE 754规格化过程中势必要损失尾部多余的二进制位。同样0.2也无法完整表示。
所以,0.1+0.2 ≈0.3
文章作者 cold-bin
上次更新 2023-08-14