八股系列|操作系统|调度算法

文章目录
调度算法
进程调度
-
FIFO
先来先服务。每次从就绪队列里调度最先进入就绪队列的进程执行,执行完毕再调度下一个次先进入就绪队列的进程执行。
**缺点:**如果长进程先进入就绪队列,会造成短进程周转时间变长,引发饥饿。
**优点:**对长进程有利,适合于CPU繁忙型的系统
-
SJF
最短作业优先调度算法。每次从就绪队列调度执行时间最短的进程执行,执行完毕再调度下一个次短的进程执行
**缺点:**会对长进程造成饥饿问题
**优点:**利于短进程,提高系统吞吐量(单位时间完成的进程数)
-
HRRN
高响应比优先调度算法。综合前两种算法优劣,每次进行进程调度时,先计算「响应比优先级」,然后把「响应比优先级」最高的进程投入运行,「响应比优先级」的计算公式:
优先权=(等待时间+要求服务时间)/要求服务时间**优点:**等待时间越长,优先级越高(利于长进程);要求服务时间越短,优先级越高(利于短进程)
**缺点:**很难估计等待时间,算法实现难度大,几乎没有现成的实现
-
RR
时间片轮转调度算法。最公平的调度算法,就绪队列里的每个进程没有优先级,依次获得相同CPU时间片使用权,时间片用完后或提前结束运行,就会调度下一个线程执行。
**优点:**不会出现进程的饥饿问题
**缺点:**没有优先级,无法即时响应紧急任务
-
HPF
最高优先级调度算法。从就绪队列中选择最高优先级的进程调度并执行。
进程的优先级可以分为,静态优先级和动态优先级:
- 静态优先级:创建进程时候,就已经确定了优先级了,然后整个运行时间优先级都不会变化;
- 动态优先级:根据进程的动态变化调整优先级,比如如果进程运行时间增加,则降低其优先级,如果进程等待时间(就绪队列的等待时间)增加,则升高其优先级,也就是随着时间的推移增加等待进程的优先级。
该算法也有两种处理优先级高的方法,非抢占式和抢占式:
- 非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
**缺点:**可能会导致低优先级的进程饥饿,甚至无法被调度执行
**优点:**能及时响应紧急任务
-
MFQ
多级反馈队列调度算法。该调度算法是综合最高优先级和时间片轮转调度算法的优劣。
**多级:**多个就绪队列,每个队列优先级从高到低,同时优先级越高时间片越短
**反馈:**新的高优先级进入就绪队列,CPU停止执行当前进程,并将其移到当前就绪队列尾部,并调度新进程执行。
过程:
- 多个就绪队列,从高到低优先级降低,并且优先级越高,时间片越短
- 新的进程会被放到第一级队列末尾,按照先来先服务原则执行,时间片用完后还没执行完毕就将其放到下一级就绪队列
- 当较高优先级就绪队列执行完毕,则下一级就绪队列开始执行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行
页面置换
-
最佳页面置换
置换在未来最长时间不访问的页面
**缺点:**无法实现预测未来,仅仅只能作为最优参考
-
先进先出置换
选择在内存驻留时间最长的页面置换。
**缺点:**可能会将频繁访问的内存驻留时间最长的页面置换出去,反而会增加后续页面置换的概率
-
最近最久未使用置换(LRU)
选择最长时间没有被访问的页面进行置换。需要为所有页面保存一个访问链表,只要访问了某页面,就将页面放到链表尾部,需要置换的时候,就置换链表首部页面,即淘汰最近最久未使用页面。
**缺点:**开销较高
**优点:**实现效果接近最佳页面置换
-
最不常用(LFU)
选择访问频率最低的页面置换。
**缺点:**没有考虑到时间维度,可能会把以前访问频率高但是近期或以后不会被访问的页面驻留在内存里;而且硬件需要为每个页面都保留一个计数器,成本太高。
磁盘调度
假设有下面一个请求序列,每个数字代表磁道的位置:
98,183,37,122,14,124,65,67
初始磁头当前的位置是在第
53磁道。
-
先来先服务
按照请求序列的顺序,移动磁头到指定磁道上。可以看出总共移动了
(98-53)+(183-98)+(183-37)+(122-37)+(122-14)+(124-14)+(124-65)+(67-65) = 640。简单粗暴,如果大量进程的请求序列分散,会导致磁头移动很距离,导致寻道时间过长,拖垮磁盘IO性能
-
最短寻道时间优先
优先选择从当前磁头位置所需寻道时间最短的请求。
所以,针对请求序列排序:65,67,37,14,98,122,124,183。磁头移动的总距离是
236磁道,相比先来先服务性能提高了不少。**缺点:**磁头有可能在一小块区域来回移动,会让某些请求饥饿。
**优点:**解决了先来先服务性能问题
-
扫描算法
最短寻道时间优先算法会产生饥饿的原因在于:磁头有可能再一个小区域内来回得移动。
为了防止这个问题,可以规定:磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向,这就是扫描(*Scan*)算法。
还是以这个序列为例子,磁头的初始位置是 53:
98,183,37,122,14,124,65,67
那么,假设扫描调度算先朝磁道号减少的方向移动,具体请求则会是下列从左到右的顺序:
37,14,
0,65,67,98,122,124,183磁头先响应左边的请求,直到到达最左端( 0 磁道)后,才开始反向移动,响应右边的请求(同理到最右端)。
缺点:由于扫描算法如果没有完成所有请求就会扫描至端点处,所以会出现中间部分被来回扫描的情况,也就是多扫了一遍
-
循环扫描法
为了解决扫描算法的缺点,循环扫描(Circular Scan, CSCAN )规定:只有磁头朝某个特定方向移动时,才处理磁道访问请求,而返回时直接快速移动至最靠边缘的磁道,也就是复位磁头,这个过程是很快的,并且返回中途不处理任何请求,该算法的特点,就是磁道只响应一个方向上的请求。
还是以这个序列为例子,磁头的初始位置是 53:
98,183,37,122,14,124,65,67
那么,假设循环扫描调度算先朝磁道增加的方向移动,具体请求会是下列从左到右的顺序:
65,67,98,122,124,183,
199,0,14,37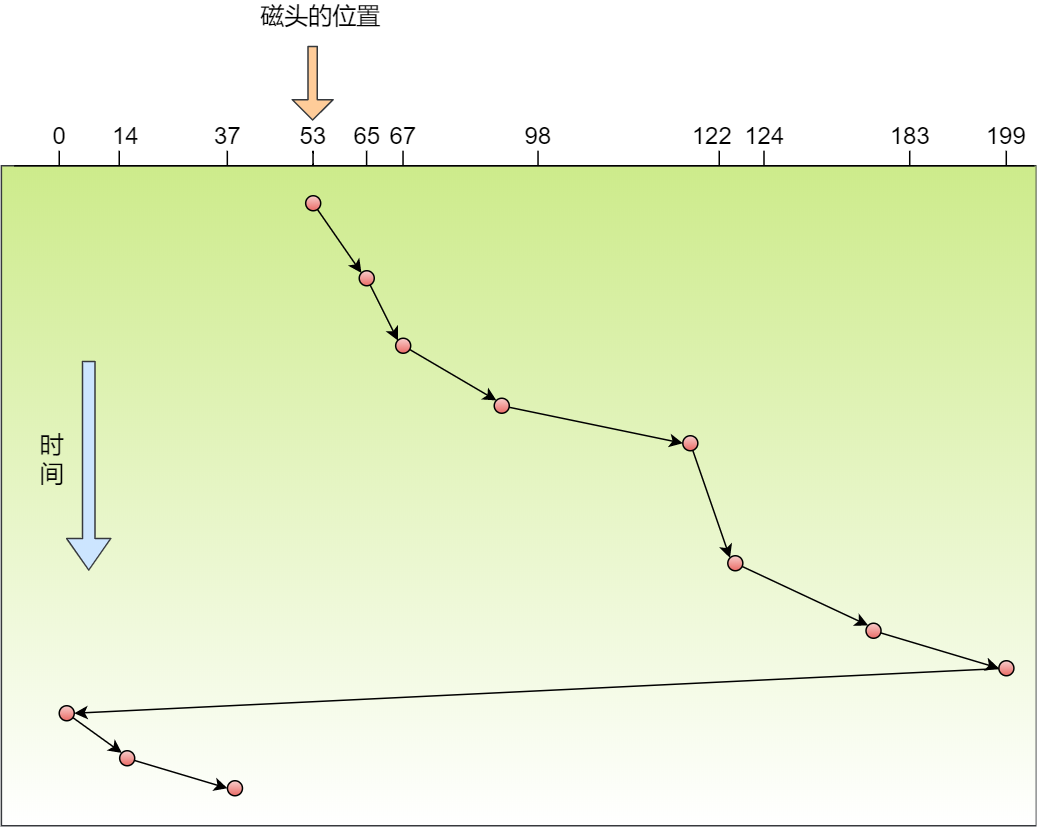
循环扫描算法相比于扫描算法,对于各个位置磁道响应频率相对比较平均。
-
LOOK 与 C-LOOK算法
我们前面说到的扫描算法和循环扫描算法,都是磁头移动到磁盘「最始端或最末端」才开始调换方向。
那这其实是可以优化的,优化的思路就是磁头在移动到「最远的请求」位置,然后立即反向移动。
那针对 SCAN 算法的优化则叫 LOOK 算法,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
而针 C-SCAN 算法的优化则叫 C-LOOK,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中不会响应请求。
文章作者 cold-bin
上次更新 2023-08-23