常见算法之并查集

文章目录
以下文章摘自
labuladong的算法小抄
并查集(Union-Find)算法
读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
并查集(Union-Find)算法是一个专门针对「动态连通性」的算法,我之前写过两次,因为这个算法的考察频率高,而且它也是最小生成树算法的前置知识,所以我整合了本文,争取一篇文章把这个算法讲明白。
首先,从什么是图的动态连通性开始讲。
#一、动态连通性
简单说,动态连通性其实可以抽象成给一幅图连线。比如下面这幅图,总共有 10 个节点,他们互不相连,分别用 0~9 标记:
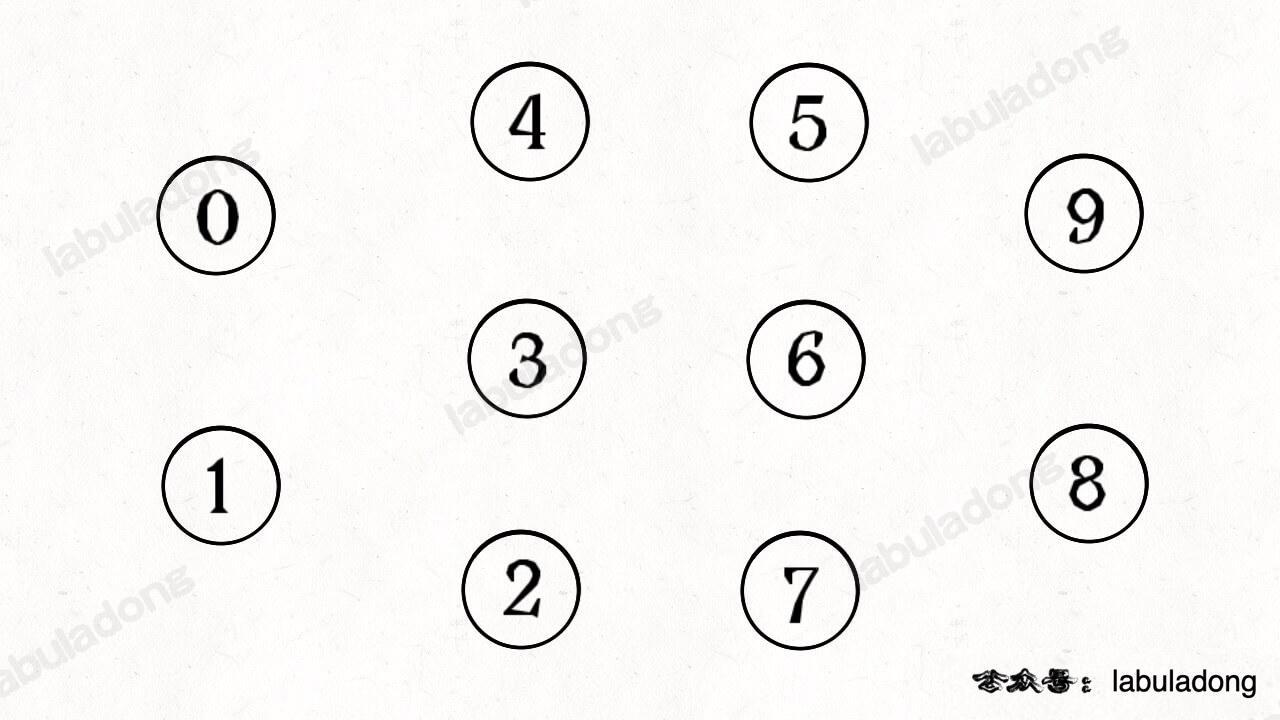
现在我们的 Union-Find 算法主要需要实现这两个 API:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点 p 和 p 是连通的。
2、对称性:如果节点 p 和 q 连通,那么 q 和 p 也连通。
3、传递性:如果节点 p 和 q 连通,q 和 r 连通,那么 p 和 r 也连通。
比如说之前那幅图,0~9 任意两个不同的点都不连通,调用 connected 都会返回 false,连通分量为 10 个。
如果现在调用 union(0, 1),那么 0 和 1 被连通,连通分量降为 9 个。
再调用 union(1, 2),这时 0,1,2 都被连通,调用 connected(0, 2) 也会返回 true,连通分量变为 8 个。
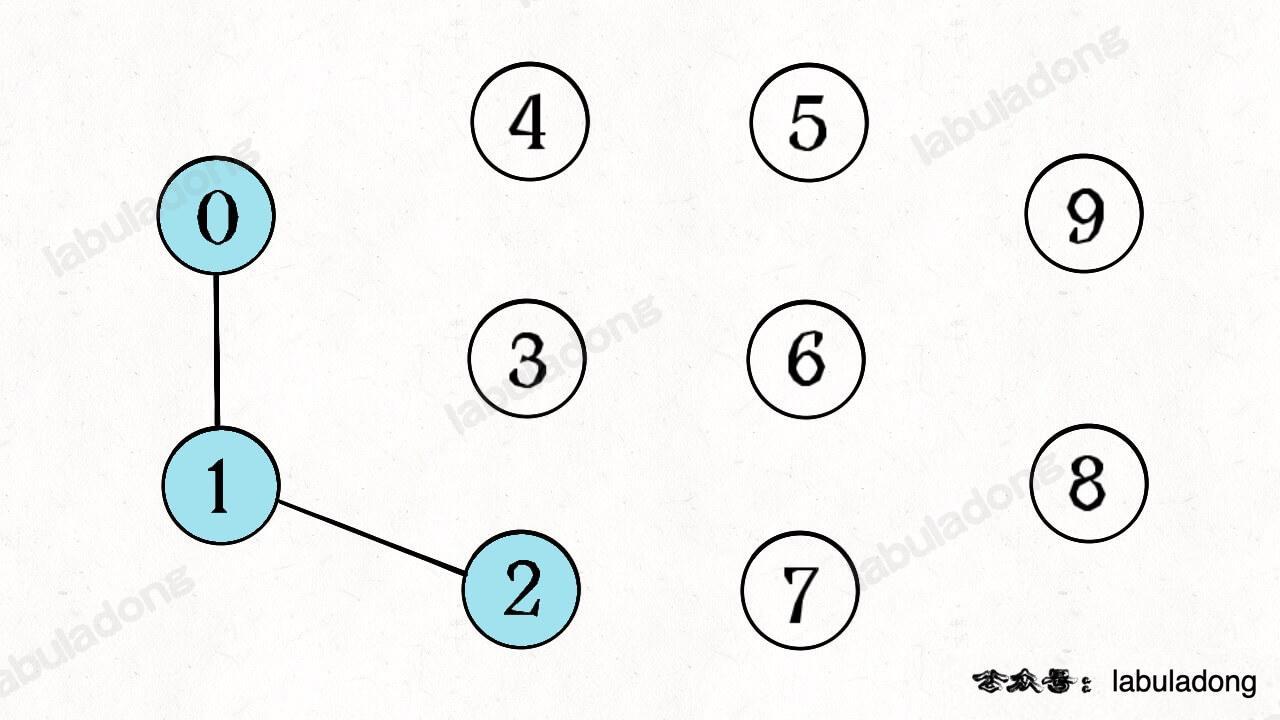
判断这种「等价关系」非常实用,比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。
这样,你应该大概明白什么是动态连通性了,Union-Find 算法的关键就在于 union 和 connected 函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
#二、基本思路
注意我刚才把「模型」和具体的「数据结构」分开说,这么做是有原因的。因为我们使用森林(若干棵树)来表示图的动态连通性,用数组来具体实现这个森林。
怎么用森林来表示连通性呢?我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。比如说刚才那幅 10 个节点的图,一开始的时候没有相互连通,就是这样:
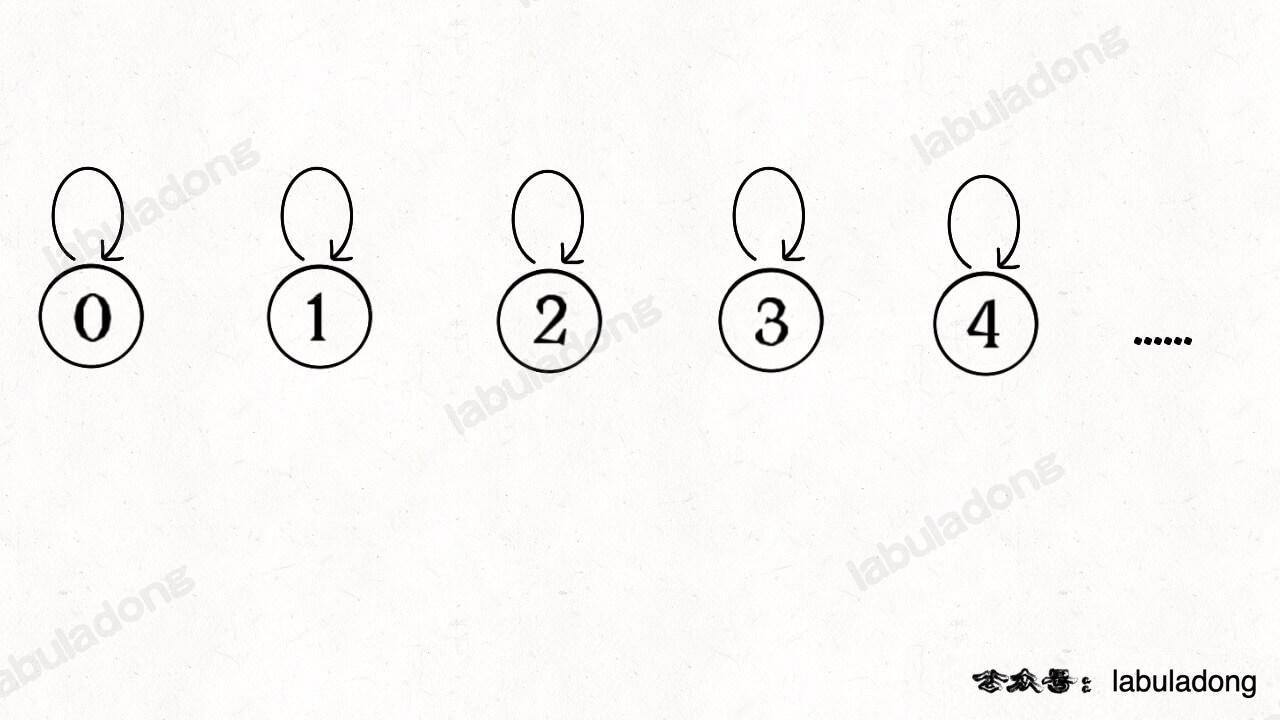
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上:
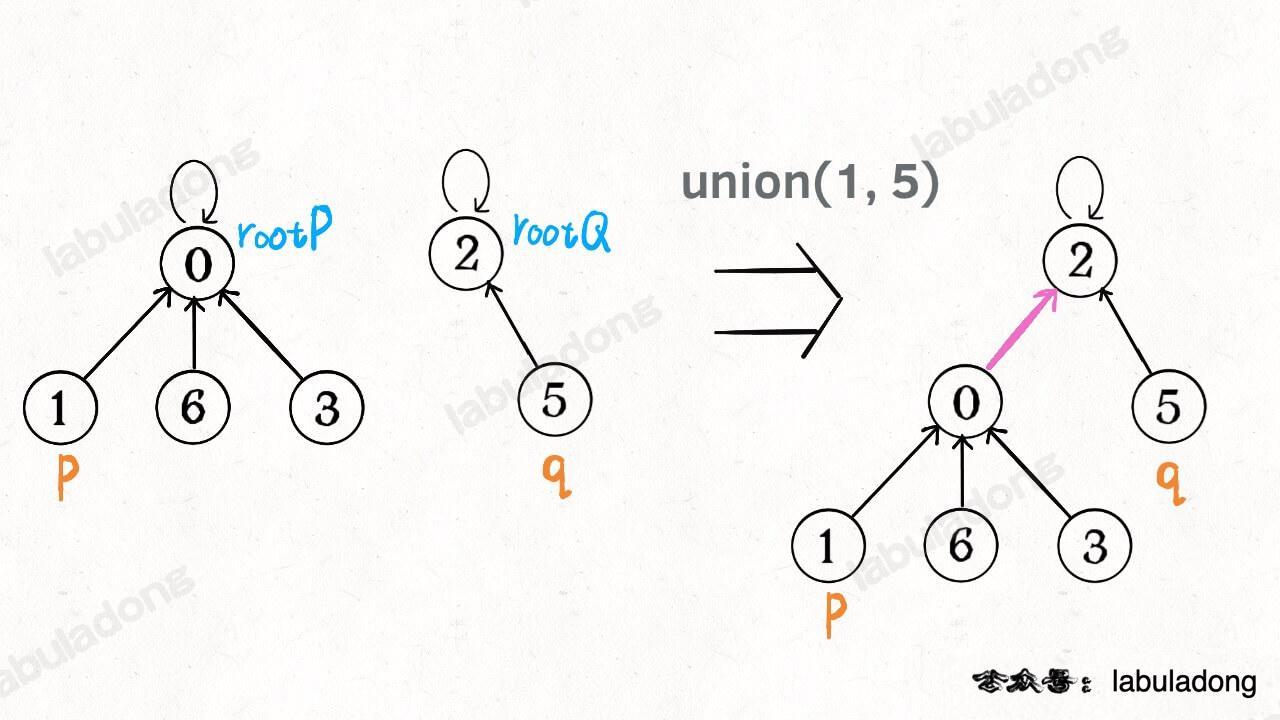
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
这样,如果节点 p 和 q 连通的话,它们一定拥有相同的根节点:
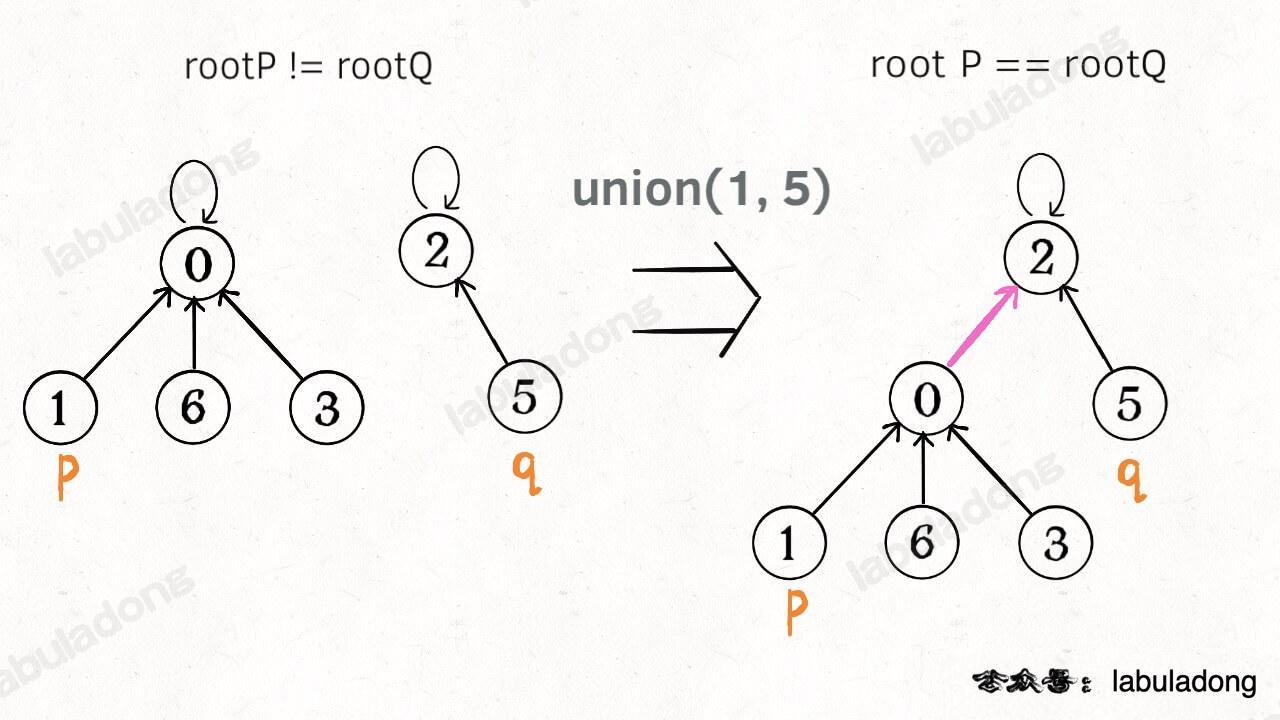
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
至此,Union-Find 算法就基本完成了。是不是很神奇?竟然可以这样使用数组来模拟出一个森林,如此巧妙的解决这个比较复杂的问题!
那么这个算法的复杂度是多少呢?我们发现,主要 API connected 和 union 中的复杂度都是 find 函数造成的,所以说它们的复杂度和 find 一样。
find 主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是 logN,但这并不一定。logN 的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成 N。
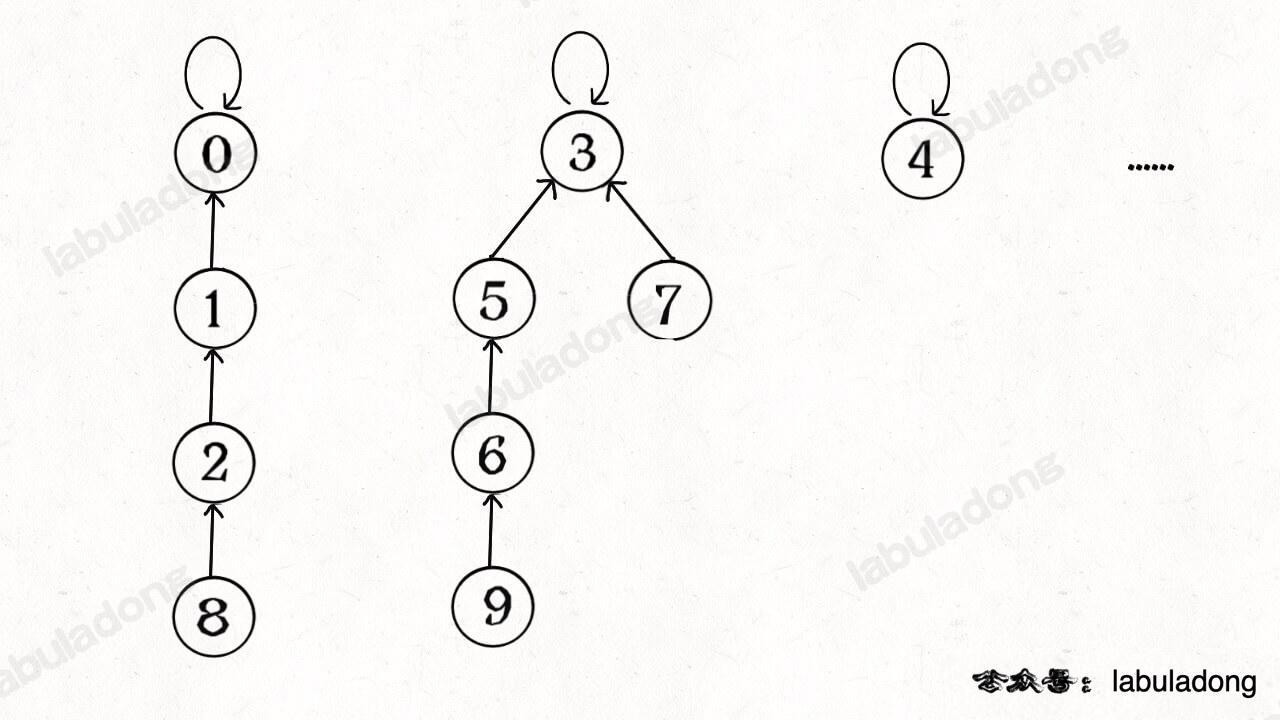
所以说上面这种解法,find , union , connected 的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于 union 和 connected 的调用非常频繁,每次调用需要线性时间完全不可忍受。
问题的关键在于,如何想办法避免树的不平衡呢?只需要略施小计即可。
#三、平衡性优化
我们要知道哪种情况下可能出现不平衡现象,关键在于 union 过程:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
我们一开始就是简单粗暴的把 p 所在的树接到 q 所在的树的根节点下面,那么这里就可能出现「头重脚轻」的不平衡状况,比如下面这种局面:
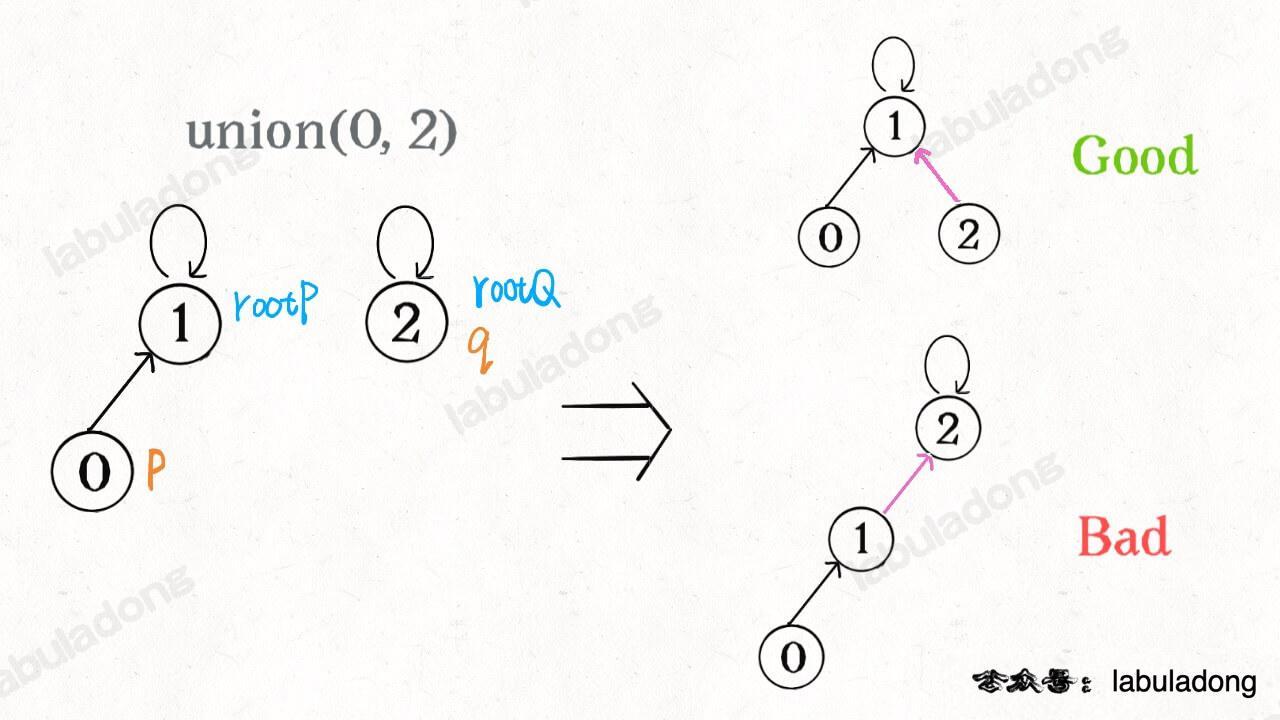
长此以往,树可能生长得很不平衡。我们其实是希望,小一些的树接到大一些的树下面,这样就能避免头重脚轻,更平衡一些。解决方法是额外使用一个 size 数组,记录每棵树包含的节点数,我们不妨称为「重量」:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
比如说 size[3] = 5 表示,以节点 3 为根的那棵树,总共有 5 个节点。这样我们可以修改一下 union 方法:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
这样,通过比较树的重量,就可以保证树的生长相对平衡,树的高度大致在 logN 这个数量级,极大提升执行效率。
此时,find , union , connected 的时间复杂度都下降为 O(logN),即便数据规模上亿,所需时间也非常少。
#四、路径压缩
这步优化虽然代码很简单,但原理非常巧妙。
其实我们并不在乎每棵树的结构长什么样,只在乎根节点。
因为无论树长啥样,树上的每个节点的根节点都是相同的,所以能不能进一步压缩每棵树的高度,使树高始终保持为常数?
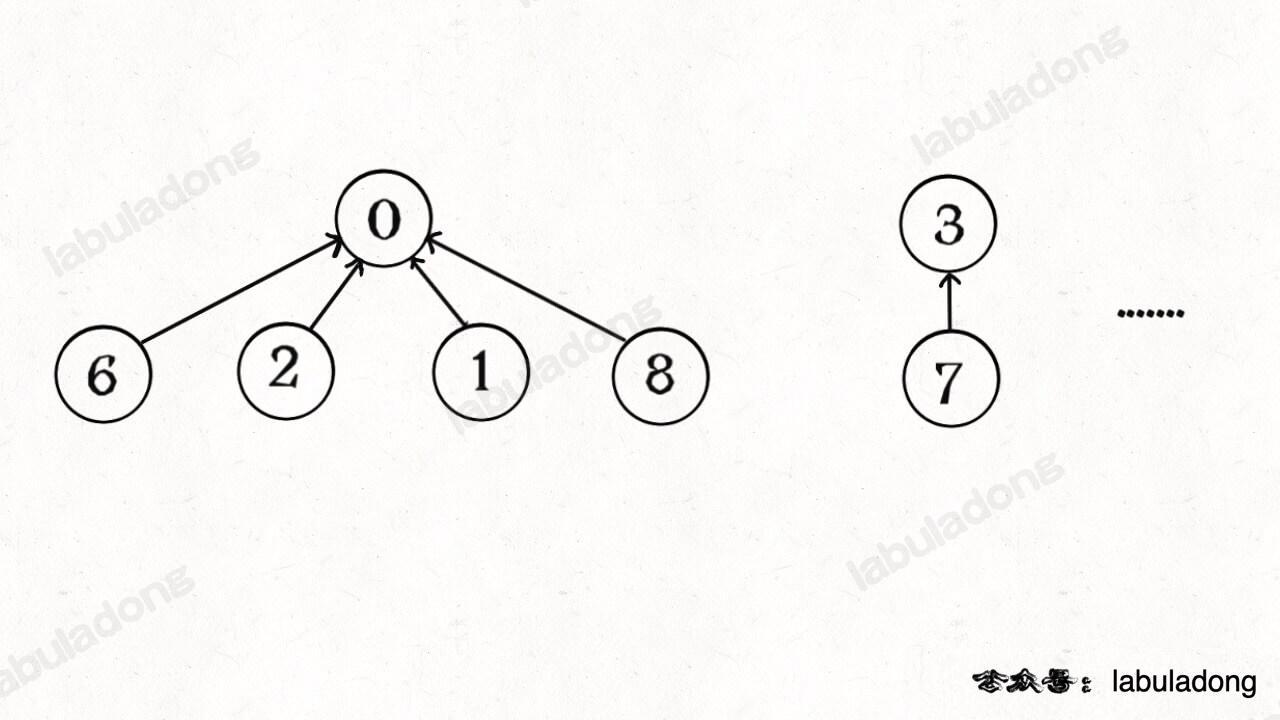
这样每个节点的父节点就是整棵树的根节点,find 就能以 O(1) 的时间找到某一节点的根节点,相应的,connected 和 union 复杂度都下降为 O(1)。
要做到这一点主要是修改 find 函数逻辑,非常简单,但你可能会看到两种不同的写法。
第一种是在 find 中加一行代码:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
这个操作有点匪夷所思,看个 GIF 就明白它的作用了(为清晰起见,这棵树比较极端):
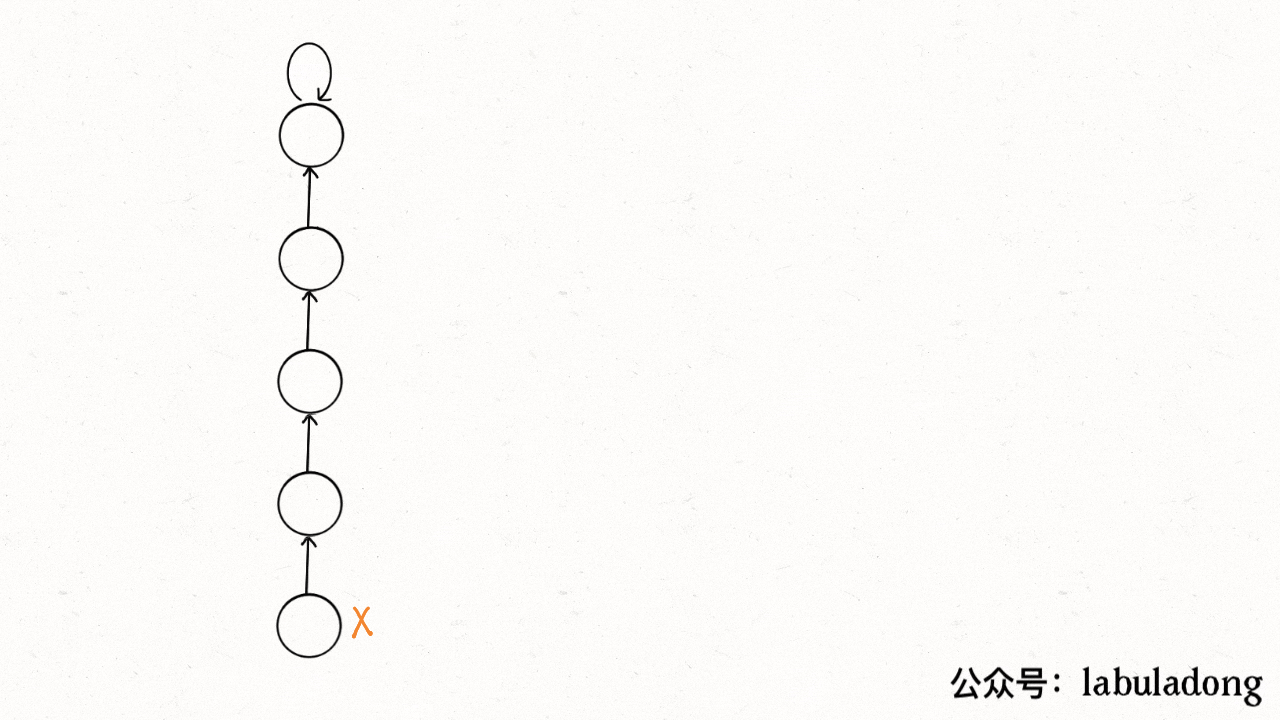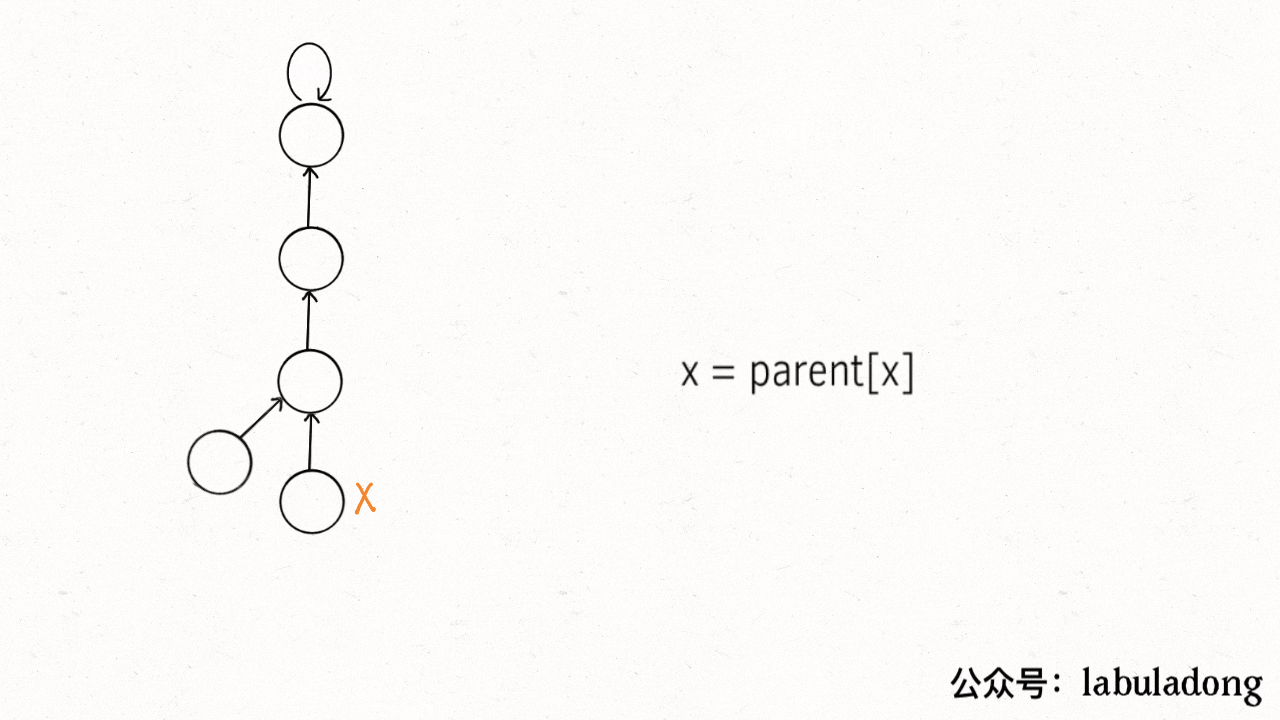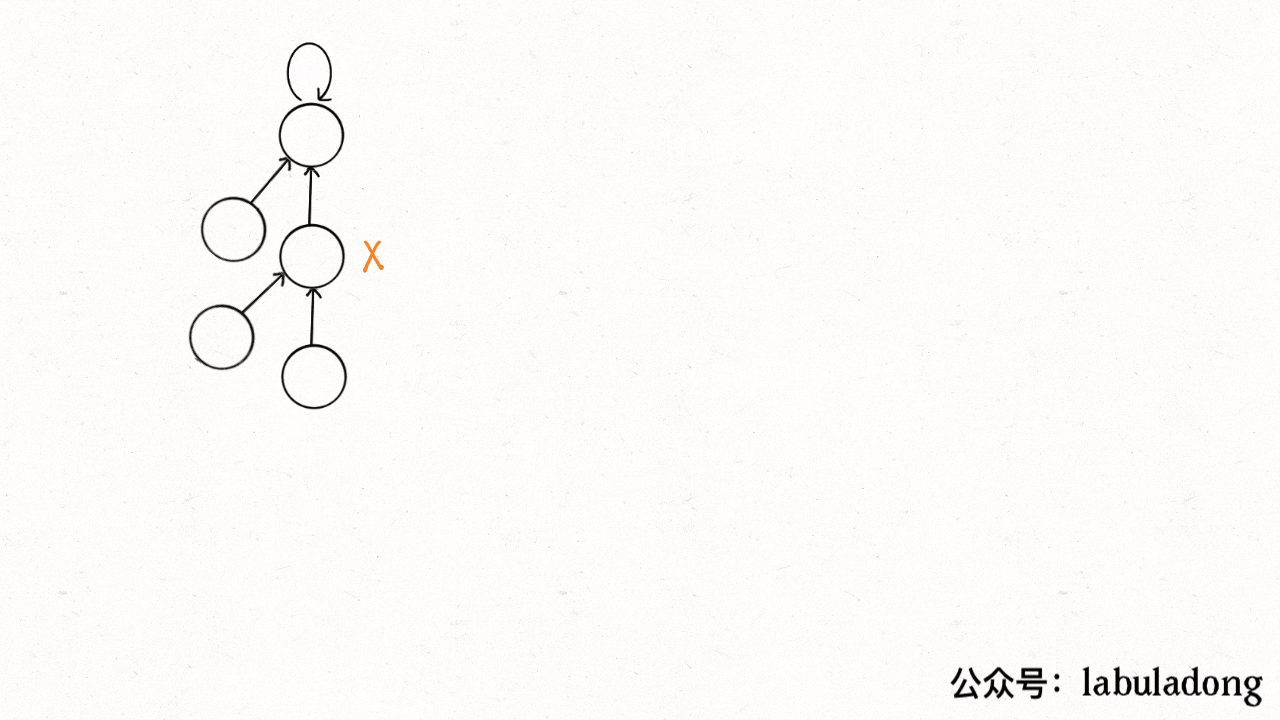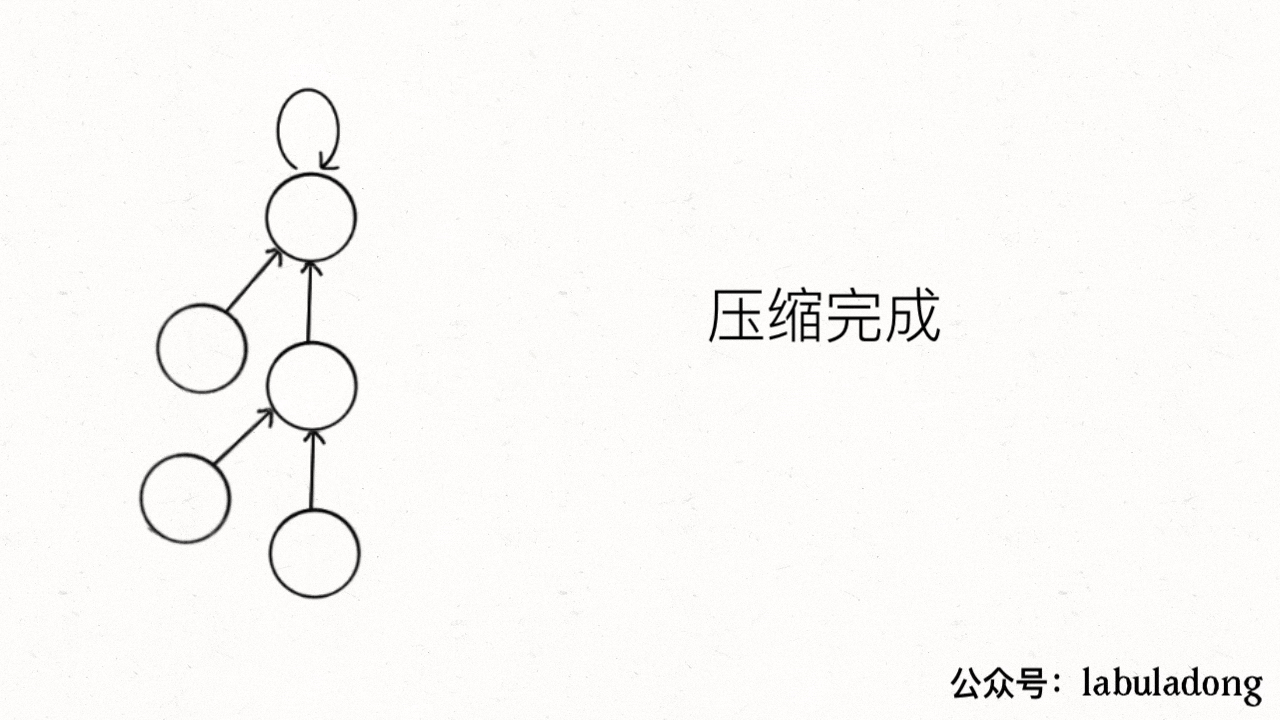
用语言描述就是,每次 while 循环都会让部分子节点向上移动,这样每次调用 find 函数向树根遍历的同时,顺手就将树高缩短了。
路径压缩的第二种写法是这样:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
我一度认为这种递归写法和第一种迭代写法做的事情一样,但实际上是我大意了,有读者指出这种写法进行路径压缩的效率是高于上一种解法的。
这个递归过程有点不好理解,你可以自己手画一下递归过程。我把这个函数做的事情翻译成迭代形式,方便你理解它进行路径压缩的原理:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
这种路径压缩的效果如下:
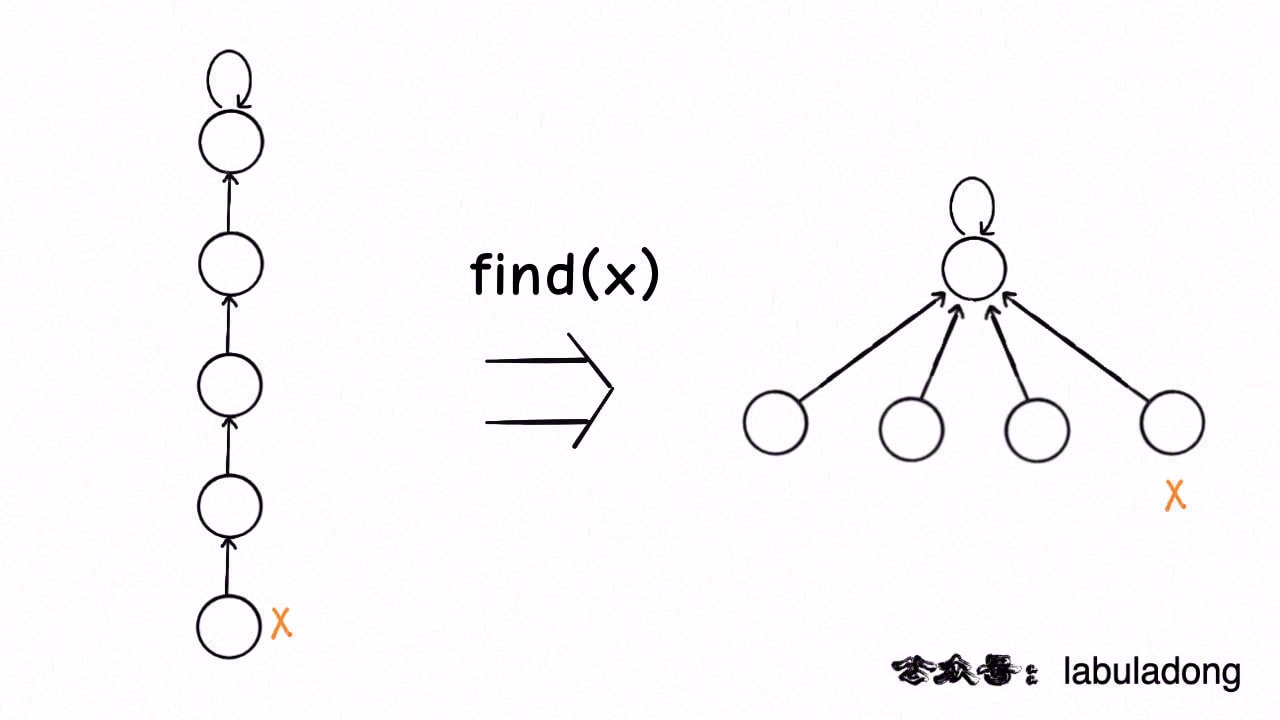
比起第一种路径压缩,显然这种方法压缩得更彻底,直接把一整条树枝压平,一点意外都没有。就算一些极端情况下产生了一棵比较高的树,只要一次路径压缩就能大幅降低树高,从 摊还分析 的角度来看,所有操作的平均时间复杂度依然是 O(1),所以从效率的角度来说,推荐你使用这种路径压缩算法。
另外,如果使用路径压缩技巧,那么 size 数组的平衡优化就不是特别必要了。所以你一般看到的 Union Find 算法应该是如下实现:
java 🟢cpp 🤖python 🤖go 🤖javascript 🤖
|
|
Union-Find 算法的复杂度可以这样分析:构造函数初始化数据结构需要 O(N) 的时间和空间复杂度;连通两个节点 union、判断两个节点的连通性 connected、计算连通分量 count 所需的时间复杂度均为 O(1)。
到这里,相信你已经掌握了 Union-Find 算法的核心逻辑,总结一下我们优化算法的过程:
1、用 parent 数组记录每个节点的父节点,相当于指向父节点的指针,所以 parent 数组内实际存储着一个森林(若干棵多叉树)。
2、用 size 数组记录着每棵树的重量,目的是让 union 后树依然拥有平衡性,保证各个 API 时间复杂度为 O(logN),而不会退化成链表影响操作效率。
3、在 find 函数中进行路径压缩,保证任意树的高度保持在常数,使得各个 API 时间复杂度为 O(1)。使用了路径压缩之后,可以不使用 size 数组的平衡优化。
文章作者 cold-bin
上次更新 2023-08-20