[toc]
拷贝
说起拷贝,语文上的联想词大概就是“复制”。那么在计算机范围内,二者定义是否一样呢?答案是不一样的。
- 拷贝:是指在计算机程序中,将一个对象的值或内容复制到另一个对象中的操作。拷贝的目的通常是为了在程序中创建一个新的、独立的对象,该对象与原始对象具有相同的值或内容,但在内存中占据不同的空间,因此它们可以被独立地修改,而互相不会影响。拷贝可以应用于各种类型的对象,包括基本类型、复合类型和自定义类型等。通常,拷贝的方式有浅拷贝和深拷贝两种,具体的拷贝方式取决于被拷贝对象的类型和需要实现的功能。
- 复制:是指在内存中创建一个新的对象,该对象是原始对象的完整副本,包括所有嵌套对象。因此,如果更改了原始对象中的可变元素,则不会影响复制对象中的相应元素,因为它们是不同的对象。复制有时也被称为深拷贝,因为它复制了对象的所有嵌套层次结构。
浅拷贝
在各大编程语言中,浅拷贝往往就是复制对象的地址
显然,浅拷贝对象之后,拷贝对象或原对象地改变将会引起另一方内容的改变。
实现
取引用或地址即可
1
2
|
int a = 1
int *b = &a
|
意义
- 保存内存空间:浅拷贝可以避免不必要的内存使用,因为它只是复制对象的一层,而不是复制对象内部的所有嵌套对象。因此,当需要创建一个新对象但又不需要完全复制原始对象时,可以使用浅拷贝。
- 提高效率:在某些情况下,使用浅拷贝可以提高代码的执行效率,因为它只复制对象的一层,而不是复制对象内部的所有嵌套对象。这意味着在处理大型数据集合时,使用浅拷贝可以提高代码的运行速度。
- 保留原始数据:浅拷贝可以在不修改原始对象的情况下创建一个新的对象,因此可以在需要保留原始数据的情况下使用。
深拷贝
相较于浅拷贝而言,深拷贝的拷贝不仅仅只是停留在引用或指针类型的表面,需要递归地获取将所有引用或指针类型的值,直到非引用或指针类型。
这样深拷贝后的对象与原对象之间没有任何指向关系,修改任意一方数据,并不会引起另一方的改变。
实现
深拷贝的定义很简单。依据定义实现的方式就是递归到非基本类型时,再拷贝这个基本值。由于不同编程语言的引用类型结构不一样,实现方式不一样。以go语言为例实现一个深拷贝示例(除了下面利用反射机制实现比较通用的深拷贝外,还可以自己手动深拷贝)
下面的实现针对有环路的数据结构会陷入无限递归的情况。需要做判环检测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
// @author cold bin
// @date 2022/10/24
package dcopy
import (
"reflect"
"time"
)
func DeepCopy(src any) any {
if src == nil {
return nil
}
original := reflect.ValueOf(src)
cpy := reflect.New(original.Type()).Elem()
copyRecursive(original, cpy)
return cpy.Interface()
}
// 递归深拷贝,直至拷贝到基础类型为止,基础类型的赋值一定是
func copyRecursive(src, dst reflect.Value) {
switch src.Kind() {
case reflect.Ptr:
// 这里主要是取出指针的实际数据,然后根据数据在反射创建一个新的指针变量,
// 更改这个指针变量的元素值,从而实现指针的深拷贝
originalValue := src.Elem()
if !originalValue.IsValid() {
return
}
dst.Set(reflect.New(originalValue.Type()))
copyRecursive(originalValue, dst.Elem())
case reflect.Interface:
// 先判断指针是否为nil,为nil就没必要继续了,直接返回到上层递归
if src.IsNil() {
return
}
originalValue := src.Elem()
copyValue := reflect.New(originalValue.Type()).Elem()
copyRecursive(originalValue, copyValue)
dst.Set(copyValue)
case reflect.Struct:
// 使用时间的程序通常应该将它们作为值,而不是指针来存储和传递。不能深度拷贝时间,貌似拷贝出来的时间都是utc
t, ok := src.Interface().(time.Time)
if ok {
dst.Set(reflect.ValueOf(t))
return
}
for i := 0; i < src.NumField(); i++ {
// TODO 跳过未导出字段,后期迭代考虑迁移到可配置的选项里
if src.Type().Field(i).PkgPath != "" {
continue
}
// 递归深拷贝直到未配置类型的非基础类型
copyRecursive(src.Field(i), dst.Field(i))
}
case reflect.Slice:
if src.IsNil() {
return
}
// 反射创建切片,从而初始化
dst.Set(reflect.MakeSlice(src.Type(), src.Len(), src.Cap()))
// 递归深拷贝切片的每个元素
for i := 0; i < src.Len(); i++ {
copyRecursive(src.Index(i), dst.Index(i))
}
case reflect.Array:
dst.Set(reflect.New(reflect.ArrayOf(src.Len(), src.Type())).Elem())
for i := 0; i < src.Len(); i++ {
copyRecursive(src.Index(i), dst.Index(i))
}
case reflect.Map:
if src.IsNil() {
return
}
dst.Set(reflect.MakeMap(src.Type()))
for _, originalKey := range src.MapKeys() {
// 取值
originalValue := src.MapIndex(originalKey)
// 复制
copyValue := reflect.New(originalValue.Type()).Elem()
// 首先对map的值递归,直到基础类型
copyRecursive(originalValue, copyValue)
// 然后再递归map的键递归,直到基础类型
copyKey := reflect.New(originalKey.Type()).Elem()
copyRecursive(originalKey, copyKey)
dst.SetMapIndex(copyKey, copyValue)
}
// TODO: 函数貌似深拷贝也没啥用
//case reflect.Func:
// if src.IsNil() {
// return
// }
// reflect.MakeFunc(src.Type(), func(in []reflect.Value) (out []reflect.Value) {
//
// })
// TODO: 反射提供的api不足以深拷贝一个 chan 好像,不知道为啥... 那暂时默认使用浅拷贝吧
//case reflect.Chan:
//if src.IsNil() {
// return
//}
//newChanV := reflect.MakeChan(src.Type(), src.Cap())
//dst.Set(newChanV)
default:
// 递归结束条件,直到未配置的类型才会被直接赋值
dst.Set(src)
}
}
|
test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// @author cold bin
// @date 2022/10/24
package dcopy
import (
"reflect"
"testing"
)
func TestCopy(t *testing.T) {
type Struct struct {
Int int
Map map[int]string
}
s := Struct{
Int: 1,
Map: map[int]string{1: "1"},
}
newS := DeepCopy(s)
s.Map[1] = "2"
if reflect.DeepEqual(s, newS) {
t.Errorf("TestCopy()=相等, want=不相等")
}
}
|
意义
- 避免对象共享:通过深拷贝,每个对象都被复制到新的内存地址中,对象之间不存在共享关系,因此对其中一个对象的修改不会影响其他对象。
- 确保拷贝对象的独立性:通过深拷贝,拷贝对象与原始对象之间完全隔离,任何一方的修改都不会影响另一方,这可以确保拷贝对象的独立性。
浅拷贝与深拷贝
区别
浅拷贝取得是地址,深拷贝拿得是内容
选择
浅拷贝得优势在于拷贝得仅仅只是对象得地址,一般来说,64位计算机里地址的大小就是8bytes大小。那么相较于深拷贝大于8字节的变量,从内存开销上来说浅拷贝更划算一点。
那么是否可以为了节约内存,我们将所有大于8字节的变量都采用浅拷贝的方式传递呢?
答案是:不可以。理由有以下几点
-
额外的计算和性能开销:因为在进行浅拷贝时,拷贝对象只是复制了原始对象的指针或引用,而其具体内容。当我们通过拷贝对象访问原始对象时,需要先访问原始对象的引用,再访问原始对象的内容,这就需要进行额外的计算开销。
举个例子,如果原始对象有一个属性名为a,我们进行了浅拷贝,得到了一个拷贝对象。当我们通过拷贝对象访问属性a时,需要先访问原始对象的引用,再访问属性a,这就需要进行额外的计算。相反,如果进行深拷贝,拷贝对象会完全复制一份,不需要额外的计算就可以访问对象。
-
对象间的相互影响:由于浅拷贝只是复制了原始对象的引用,所以当拷贝对象修改了某个属性或方法时,原始对象也会受到影响。这种相互影响可能导致程序出现不可预期的行为。
-
并发访问问题:当多个线程或者协程同时访问同一个对象的拷贝时,可能会导致数据竞争或者锁争用等并发问题。
-
增加GC的压力:指针可以导致内存泄漏。如果一个指针指向的对象没有被及时释放,就会一直占用内存,造成内存泄漏。这个问题可以通过使用垃圾回收来解决,但是如果过度使用指针,就会导致垃圾回收器无法及时回收内存,从而增加内存使用量和垃圾回收时间。
一方面,针对一些比较大的数据,我们可以进行浅拷贝,以避免深拷贝带来的性能耗损问题;另一方面,大规模使用浅拷贝也会带来一系列问题,应当避免大规模的浅拷贝使用。
当然,原对象和拷贝对象是否相互关联,依据业务而定来选择深浅拷贝
零拷贝
零拷贝是指计算机执行I/O操作时,CPU不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及CPU的拷贝时间。它是一种I/O操作优化技术。
DMA
DMA,英文全称是Direct Memory Access,即直接内存访问。DMA允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与。
主要干的事情就是:转发CPU的IO请求以及从外设设备哪里拷贝数据到内存里
相当于DMA在IO数据传送上,可以去分担CPU的活儿,让CPU可以去干其他事情,变相地提高了CPU的工作效率。暂时可以把DMA当作一个小CPU来看待
传统的I/O
过程
以文件下载服务为例
read:把数据从磁盘读取到内核缓冲区,再拷贝到用户缓冲区write:先把用户缓冲区数据写入到内核socket缓冲区,最后写入网卡设备。
流程如下图:

依据上图我们可以得知:传统IO的读写流程,包括了4次上下文切换,4次数据拷贝
零拷贝的几种实现
传统的IO操作具有4次上下文切换,4次数据拷贝。我们可以使用零拷贝的方式来减少上下文的切换和数据拷贝的次数,从而大大提高IO的效率
mmap+write
什么是mmap?
mmap在linux和windows均已实现
mmap是一种将文件/设备映射到内存的方法,实现文件的磁盘地址和进程虚拟地址空间中的一段虚拟地址的一一映射关系。也就是说,可以在某个进程中通过操作这一段映射的内存,实现对文件的读写等操作。修改了这一段内存的内容,文件对应位置的内容也会同步修改,而读取这一段内存的内容,相当于读取文件对应位置的内容。
先看过程图

依据上图我们可以得到:mmap+write的方式可以减少一次CPU拷贝。但是上下文的切换依然是4次
mmap就是利用虚拟内存,可以把内核空间和用户空间的虚拟地址映射到同一个物理地址,从而减少数据拷贝次数!mmap就是用了虚拟内存这个特点,它将内核中的读缓冲区与用户空间的缓冲区进行映射,所有的IO都在内核中完成
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
// windows下
package main
import (
"os"
"syscall"
"unsafe"
)
const defaultMaxFileSize = 1 << 20 // 假设文件最大为 1M
const defaultMemMapSize = 1 << 20 // 假设映射的内存大小为 1M
type Mmap struct {
file *os.File // file 即文件描述符
data *[defaultMaxFileSize]byte // data 是映射内存的起始地址
}
func (demo *Mmap) mmap() {
// 需要 CreateFileMapping 和 MapViewOfFile 两步才能完成内存和文件的映射
h, err := syscall.CreateFileMapping(syscall.Handle(demo.file.Fd()), nil, syscall.PAGE_READWRITE, 0, defaultMemMapSize, nil)
if err != nil {
panic(err)
}
addr, err := syscall.MapViewOfFile(h, syscall.FILE_MAP_WRITE, 0, 0, uintptr(defaultMemMapSize))
if err != nil {
panic(err)
}
err = syscall.CloseHandle(syscall.Handle(h))
if err != nil {
panic(err)
}
// 这里将映射的内存地址直接转化为byte数组的地址,这样就形成了完整的映射关系:修改映射区域的内存就会引起文件内容修改
demo.data = (*[defaultMaxFileSize]byte)(unsafe.Pointer(addr))
}
// 取消映射
func (demo *Mmap) munmap() {
// 先拿一下映射的data地址值
addr := (uintptr)(unsafe.Pointer(&demo.data[0]))
// 再调一下api取消这个地址的映射
if err := syscall.UnmapViewOfFile(addr); err != nil {
panic(err)
}
}
func main() {
f, _ := os.OpenFile("tmp.txt", os.O_CREATE|os.O_RDWR, 0644)
demo := &Mmap{file: f}
demo.mmap()
defer demo.munmap()
msg := "tmp.txt你好呀 ^% *sda ..a"
for i := 0; i < len(msg); i++ {
demo.data[i] = msg[i]
}
}
|
sendfile
sendfile是linux下的api,windows上没有
sendfile表示在两个文件描述符之间传输数据,它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,因此可以使用它来实现零拷贝。
过程如下图
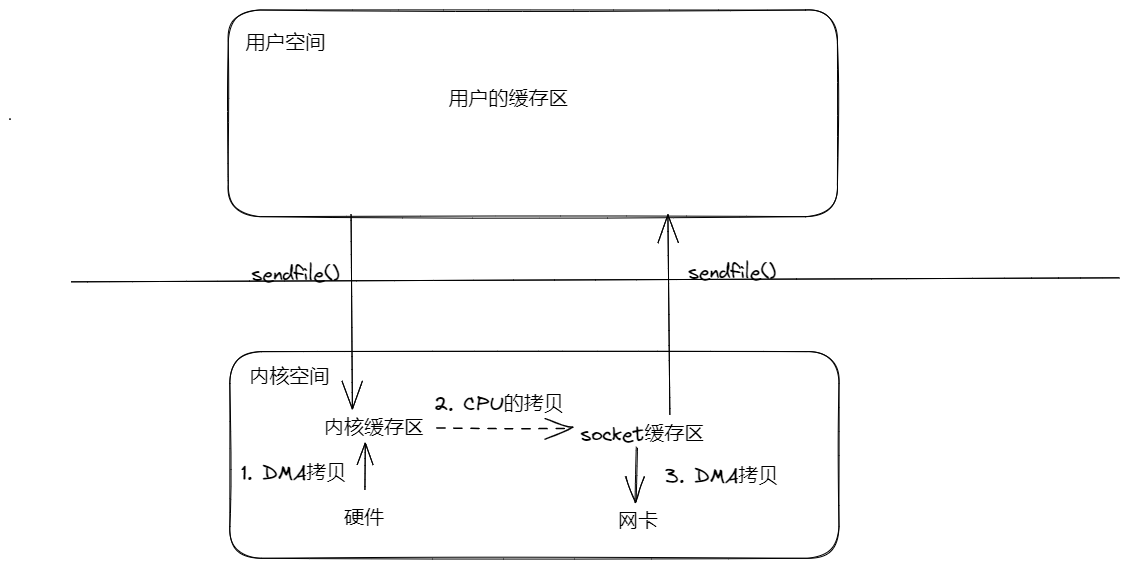
可以看出,上下文切换只有2次,CPU的数据拷贝是1次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// 在linux系统下运行
package main
import (
"log"
"os"
"syscall"
)
func main() {
srcFile, err := os.Open("src.txt")
if err != nil {
log.Fatal(err)
}
defer srcFile.Close()
dstFile, err := os.Create("dst.txt")
if err != nil {
log.Fatal(err)
}
defer dstFile.Close()
src := int(srcFile.Fd())
dst := int(dstFile.Fd())
for {
// 将 src 文件描述符中的数据传输到 dst 文件描述符中、
// linux系统下,sendfile有限制,需要批量sendfile
n, err := syscall.Sendfile(dst, src, nil, 4096)
if err != nil {
log.Fatal(err)
}
if n == 0 {
break
}
}
log.Println("Data transfer completed.")
}
|
