锁

文章目录
[toc]
定义
顾名思义,锁就是可以锁住某些东西的东西。在计算机科学中,锁(lock)是一种同步机制,用于在有许多执行线程的环境中强制对资源的访问限制。锁旨在强制实施互斥排他、并发控制策略。
所谓的锁,可以理解为内存中的一个整型数或者一个结构体对象,拥有两种状态:空闲状态和上锁状态。加锁时,判断锁是否空闲,如果空闲,修改为上锁状态,返回成功;如果已经上锁,则返回失败。解锁时,则把锁状态修改为空闲状态。
过程:
|
|
由上面的锁的控制过程可以知道:我们可以利用这种结构来作为资源的并发监视:将并发资源与锁进行匹配,一旦某个线程对当前资源发起读写操作,为了保证数据并发安全,需要将当前资源进行上锁。
应用场景及分类
-
互斥锁
一次只能一个线程拥有互斥锁,其他线程只有等待。互斥锁是在抢锁失败的情况下主动放弃CPU进入睡眠状态直到锁的状态改变时再唤醒,互斥锁在加锁操作时涉及上下文的切换。
-
自旋锁
在任何时刻同样只能有一个线程访问对象(这点和互斥锁一样)。**但是当获取锁操作失败时,不会进入睡眠,而是会在原地“自旋”,直到锁被释放。**这样节省了线程从睡眠状态到被唤醒期间的消耗,在加锁时间短暂的环境下会极大的提高效率。但如果加锁时间过长,则会非常浪费CPU资源。一直让锁跑在CPU上轮询锁是否释放。因此,自旋锁比较适用于加锁时间较短的场景,如果加锁时间过长的话,可以考虑使用互斥锁,直接放弃CPU进入睡眠。
golang可以通过runtime提供的原子操作
CompareAndSwapInt32(即CAS)来做一个简易的自旋锁。实现的效果:- 只有第一个来获取锁的能成功(即 Swap),其他的由于 old 对不上,所以 CAS 的返回值 swapped 为 false;
- 无法获取锁的 goroutine 进入自旋(也就是先休眠,过一段时间继续探测能否获取锁)。
1 2 3 4 5 6 7 8for { // 如果num2这个变量旧值为10那么会被成功修改为0,如果不为10,那么不会被修改就会一直在CPU原地地自旋直到出现10或超时 if atomic.CompareAndSwapInt32(&num2, 10, 0) { fmt.Println("The second number has gone to zero.") break } time.Sleep(time.Millisecond * 500) } -
读写锁–共享-独占锁
读写锁是特殊的自旋锁。特性是读共享,写互斥。一次只有一个线程可以占有写模式的读写锁, 但是可以有多个线程同时占有读模式的读写锁。
-
悲观锁
顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
但是悲观锁本身比较悲观,比较得浪费资源:悲观地认为每次操作都是写操作,每次操作都会上锁来保证写操作的数据同步。但是真实的业务场景不一定是写多读少,例如日志存档这种应用场景,几乎只有
insert和select操作。所以,契合这种读多写少的业务场景,可以使用乐观锁的机制来保证数据的并发安全。只要不在内存真的生成一个互斥锁的内部结构,这样就要性能稍微好点,一旦发生锁的阻塞,可能会涉及上下文的切换和锁等待,比较耗费系统资源
-
乐观锁
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号或时间戳等机制。乐观锁适用于多读少写的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,又或者说数据表的版本号,其实都是提供的乐观锁。
但是针对写多读少的场景,乐观锁就显得捉襟见肘勒。假设一段时间内服务器收到了大量的请求,其中大部分请求都是DML,少部分请求是DQL。那么采用乐观锁的机制来实现并发安全机制,就会使得短时间内会有大量的DML失败返回,然后不断重试直到成功。在系统外部来看,这感觉像是一个事故。因此针对写多读少的场景应该考虑使用悲观锁来保证数据的并发安全。
-
信号量
是用于线程间同步和互斥的,当一个线程完成操作后就通过信号量通知其它线程,然后别的线程就可以继续进行某些操作。
Go语言的惯用法就是将带缓冲 channel 用作计数信号量。带缓冲channel中的当前数据个数代表的是当前同时处于活动状态的goroutine的数量,而带缓冲channel的容量就代表了允许同时处于活动状态的goroutine的最大数量。
向带缓冲 channel 的一个发送操作表示获取一个信号量,而从 channel 的一个接收操作则表示释放一个信号量。
计数信号量经常被使用于限制最大并发数,例如:实现一个同一时间允许的最多5个goroutine工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32package main import ( "log" "sync" "time" ) func main() { active := make(chan struct{}, 5) // 代表允许同时活跃G的数量 jobs := make(chan int, 10) // 代表G的最大数量 go func() { for i := 0; i < 8; i++ { jobs <- i + 1 } close(jobs) }() var wg sync.WaitGroup for j := range jobs { wg.Add(1) active <- struct{}{} go func(j int) { defer func() { <-active }() log.Printf("handle job: %d\n", j) time.Sleep(2 * time.Second) wg.Done() }(j) } wg.Wait() }不要通过共享内存进行通信。建议,通过通信来共享内存。(Do not communicate by sharing memory; instead, share memory by communicating) – Go 语言并发
应用实例
MySQL的并发事务访问记录的问题
以InnoDB引擎为例,并发事务访问相同记录的情况大致可以划分为3种:
读-读情况
读-读情况,即并发事务相继读取相同的记录。读取操作本身不会对记录有任何影响,并不会引起什么问题,所以允许这种情况的发生。(读写锁)
写-写情况
写-写情况,即并发事务相继对相同的记录做出改动。
在这种情况下可能会发生脏写的问题,任何一种隔离级别都不允许这种问题的发生。所以在多个未提交事务相继对一条记录做改动时,需要让它们排队执行,这个排队的过程其实是通过锁来实现的。这个锁其实是一个内存中的结构 ,在事务执行前本来是没有锁的,也就是说一开始是没有锁结构和记录进行关联的,如图所示:

当一个事务想对这条记录做改动时,首先会看看内存中有没有与这条记录关联的锁结构,当没有的时候就会在内存中生成一个锁结构与之关联。比如,事务 T1要对这条记录做改动,就需要生成一个锁结构与之关联:
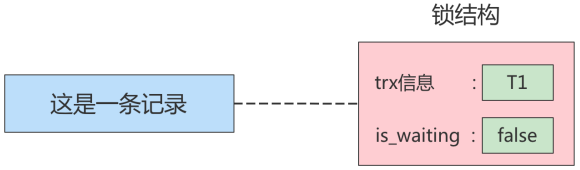
在锁结构里有很多信息,为了简化理解,只把两个比较重要的属性拿了出来:
trx信息:代表这个锁结构是哪个事务生成的。is_waiting:代表当前事务是否在等待。
在事务T1改动了这条记录后,就生成了一个锁结构与该记录关联,因为之前没有别的事务为这条记录加锁,所以is_waiting属性就是false,我们把这个场景就称值为获取锁成功,或者加锁成功,然后就可以继续执行操作了。
在事务T1提交之前,另一个事务T2也想对该记录做改动,那么先看看有没有锁结构与这条记录关联,发现有一个锁结构与之关联后,然后也生成了一个锁结构与这条记录关联,不过锁结构的is_waiting属性值为true,表示当前事务需要等待,我们把这个场景就称之为获取锁失败,或者加锁失败,图示:
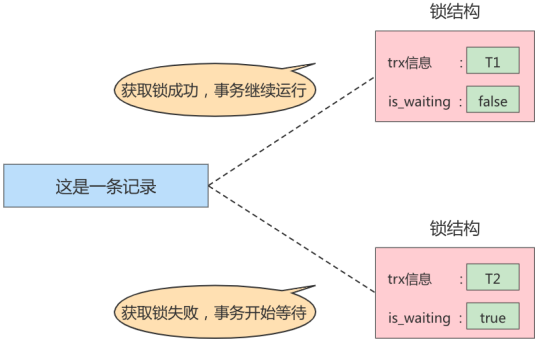
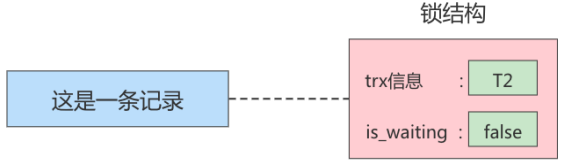
在事务T1提交之后,就会把该事务生成的锁结构释放掉,然后看看还有没有别的事务在等待获取锁,发现了事务T2还在等待获取锁,所以把事务T2对应的锁结构的is_waiting属性设置为false,然后把该事务对应的线程唤醒,让它继续执行,此时事务T2就算获取到锁了。效果就是这样。
小结
-
不加锁
意思就是不需要在内存中生成对应的锁结构,可以直接执行操作。
-
获取锁成功,或者加锁成功
意思就是在内存中生成了对应的锁结构,而且锁结构的
is_waiting属性为false,也就是事务可以继续执行操作。 -
获取锁失败,或者加锁失败,或者没有获取到锁
意思就是在内存中生成了对应的锁结构,不过锁结构的
is_waiting属性为true,也就是事务需要等待,不可以继续执行操作。
读-写或写-读情况
读-写或写-读,即一个事务进行读取操作,另一个进行改动操作。这种情况下可能发生脏读、不可重复读、幻读的问题。
各个数据库厂商对SQL标准的支持都可能不一样。比如MySQL在REPEATABLE READ隔离级别上就已经解决了幻读问题(MVCC–>快照读+next-key lock–>当前读)。
并发问题的解决方案
怎么解决脏读、不可重复读、幻读这些问题呢?其实有两种可选的解决方案:
-
方案一:读操作利用多版本并发控制(MVCC),写操作进行加锁(next-key lock)。——MySQl8.0默认的
REPEATABLE READ隔离级别所谓的MVCC,就是生成一个ReadView,通过ReadView找到符合条件的记录版本(历史版本由undo log版本单链表构建)。查询语句只能读到在生成ReadView之前已提交事务所做的更改,在生成ReadView之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而写操作肯定针对的是最新版本的记录,读记录的历史版本和改动记录的最新版本本身并不冲突,也就是采用MVCC时,读-写操作并不冲突。
在
REPEATABLE READ隔离级别下,一个事务在执行过程中只有第一次执行SELECT操作才会生成一个ReadView,之后的SELECT操作都复用这个ReadView,这样也就避免了不可重复读和幻读的问题所谓next-key lock就是临键锁:会根据查询等语句的原义,将扫描到的间隙范围加上锁,这样就能防止一个事务执行过程中相同查询语句出现“幻影”记录。
-
方案二:读、写操作都采用加锁的方式。
如果我们的一些业务场景不允许读取记录的旧版本,而是每次都必须去读取记录的最新版本。
比如,在银行存款的事务中,你需要先把账户的余额读出来,然后将其加上本次存款的数额,最后再写到数据库中。在将账户余额读取出来后,就不想让别的事务再访问该余额,直到本次存款事务执行完成,其他事务才可以访问账户的余额。这样在读取记录的时候就需要对其进行加锁操作,这样也就意味着读操作和写操作也像写-写操作那样排队执行。
脏读的产生是因为当前事务读取了另一个未提交事务写的一条记录,如果另一个事务在写记录的时候就给这条记录加锁,那么当前事务就无法继续读取该记录了,所以也就不会有脏读问题的产生了。
不可重复读的产生是因为当前事务先读取一条记录,另外一个事务对该记录做了改动之后并提交,当前事务再次读取时会获得不同的值,如果在当前事务读取记录时就给该记录加锁,那么另一个事务就无法修改该记录,自然也不会发生不可重复读了。
幻读问题的产生是因为当前事务读取了一个范围的记录,然后另外的事务向该范围内插入了新记录,当前事务再次读取该范围的记录时发现了新插入的新记录。采用加锁的方式解决幻读问题就有一些麻烦,因为当前事务在第一次读取记录时幻影记录并不存在,所以读取的时候加锁就有点尴尬(因为你并不知道给谁加锁)。
MySQL最高隔离级别,事务之间串行化执行,就避免了所有那四大问题
小结
- 采用MVCC方式的话,读-写操作彼此并不冲突性能更高。
- 采用加锁方式的话,读-写操作彼此需要排队执行,影响性能。
一般情况下我们当然愿意采用MVCC来解决读-写操作并发执行的问题,但是业务在某些特殊情况下,要求必须采用加锁的方式执行。
文章作者 cold-bin
上次更新 2022-11-09