Go的结构体内存对齐

文章目录
一. 什么是内存对齐, 为啥要内存对齐?
在解释什么是内存对齐之前,我们需要先了解一下CPU和内存数据交互的过程。CPU和内存是通过总线进行数据交互的。其中地址总线用来传递CPU需要的数据地址,内存将数据通过数据总线传递给CPU, 或者CPU将数据通过数据总线回传给内存。
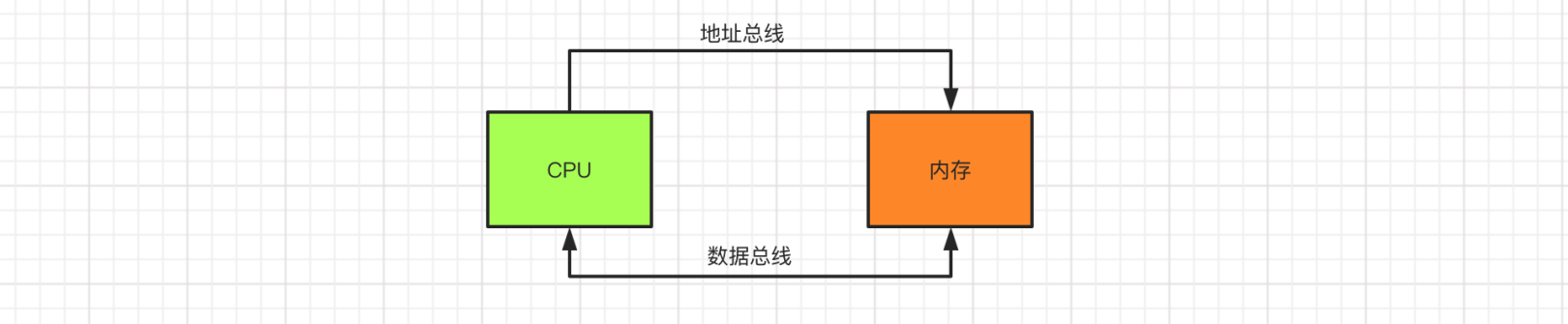
首先我们需要知道以下概念:
(1) 机器字长
在计算机领域,对于某种特定的计算机设计而言,字(word)是用于表示其自然的数据单位的术语,是用来表示一次性处理事务的固定长度。一个字的位数,即字长。
(2) 地址总线
专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向的。地址总线的位数决定了CPU可直接寻址的内存空间大小,比如8位微型机的地址总线为16位,则其最大可寻址空间为2^16=64KB,16位微型机的地址总线为20位,其可寻址空间为2^20=1MB。
(3) 数据总线
是CPU与内存或其他器件之间的数据传送的通道。每条传输线一次只能传输1位二进制数据, 数据总线每次可以传输的字节总数就称为机器字长或者数据总线的宽度。 它决定了CPU和外界的数据传送速度。我们现在日常使用的基本上是32位(每次可以传输4字节)或者64位(每次可以传输8字节)机器字长的机器。
由于数据是通过总线进行传输,若数据未经一定规则的对齐,CPU的访址操作与总线的传输操作将会异常的复杂,所以编译器在程序编译期间会对各种类型的数据按照一定的规则进行对齐, 对齐过程会按一定规则对内存的数据段进行的字节填充, 这就是字节对齐。
例如: 现在要存储变量A(int32)和B(int64)那么不做任何字节对齐优化的情况下,内存布局是这样的

字节对齐优化后是这样子的:

一看感觉字节对齐后浪费了内存, 但是当我们去读取内存中的数据给CPU时,64位的机器(一次可以原子读取8字节)在内存对齐和不对齐的情况下A变量都只需要原子读取一次就行, 但是对齐后B变量的读取只需一次, 而不对齐的情况下,B需要读取2次,且需要额外的处理牺牲性能来保证2次读取的原子性。所以本质上,内存填充是一种以空间换时间, 通过额外的内存填充来提高内存读取的效率的手段。
总的来说,内存对齐主要解决以下两个问题:
【1】跨平台问题:如果数据不对齐,那么在64位字长机器存储的数据可能在32位字长的机器可能就无法正常的读取。
【2】性能问题:如果不对齐,那么每个数据要通过多少次总线传输是未知的,如果每次都要处理这些复杂的情况,那么数据的读/写性能将会收到很大的影响。之所以有些CPU支持访问任意地址,是因为处理器在后面多做了很多额外处理。
二. 内存对齐的规则是什么?
内存对齐主要是为了保证数据的原子读取, 因此内存对齐的最大边界只可能为当前机器的字长。当然如果每种类型都使用最大的对齐边界,那么对内存将是一种浪费,实际上我们只要保证同一个数据不要分开在多次总线事务中便可。
Go在其官方文档 Size and alignment guarantees - Golang spec 就描述了其在内存对齐方面的细节。
Go也提供了unsafe.Alignof(x)来返回一个类型的对齐值,并且作出了如下约定:
- 对于任意类型的变量 x ,
unsafe.Alignof(x)至少为 1。 - 对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的
unsafe.Alignof(x.f),unsafe.Alignof(x)等于其中的最大值。 - 对于 array 数组类型的变量 x,
unsafe.Alignof(x)等于构成数组的元素类型的对齐倍数。 - 没有任何字段的空 struct{} 和没有任何元素的 array 占据的内存空间大小为 0,不同的大小为 0 的变量可能指向同一块地址。
总结来说,分为基本类型对齐和结构体类型对齐
(1) 基本类型对齐
go语言的基本类型的内存对齐是按照基本类型的大小和机器字长中最小值进行对齐
| 数据类型 | 类型大小(32/64位) | 最大对齐边界(32位) | 最大对齐边界(64位) |
|---|---|---|---|
| int8/uint8/byte | 1字节 | 1 | 1 |
| int16/uint16 | 2字节 | 2 | 2 |
| int32/uint32/rune/float32/complex32 | 4字节 | 4 | 4 |
| int64/uint64/float64/complex64 | 8字节 | 4 | 8 |
| string | 8字节/16字节 | 4 | 8 |
| slice | 12字节/24字节 | 4 | 8 |
我们可以在自己的机器上编码测试了一下(我的机器是64位的 Mac OS X):
|
|
复制
运行结果:
|
|
复制
(2) 结构体类型对齐
go语言的结构体的对齐是先对结构体的每个字段进行对齐,然后对总体的大小按照最大对齐边界的整数倍进行对齐。有一个特殊的情况就是,如果空结构体嵌套到一个结构体尾部,那么这个结构体也是要额外对齐的,因为如果有指针指向该字段, 返回的地址将在结构体之外,如果此指针一直存活不释放对应的内存,就会有内存泄露的问题。
下面通过一些列的例子来说明一下结构体对齐的规则,需要额外说明的是结构体内的字段位置其实都是通过计算到结构体首地址的偏移量来确定的,对所有的字段来说,首地址就是结构体内索引值为0的地址。
案例一
|
|
复制
TestStruct1在编译期就会进行字节对齐的优化。优化后各个变量的相对位置如下图(以64位字长下环境为例):
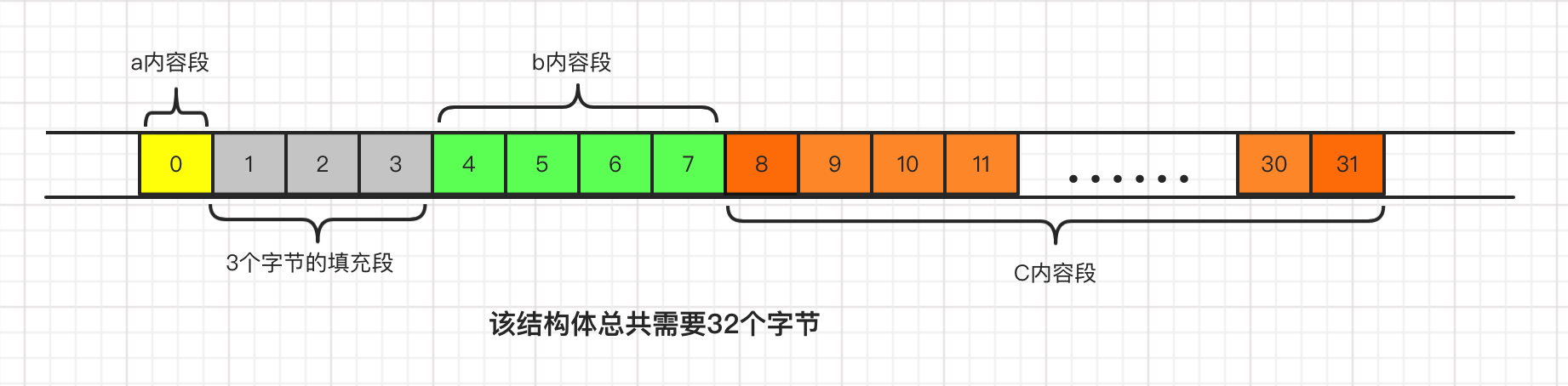 image.png
image.png
TestStruct1 内存占用大小分析:最大对齐边界为8,总体字节数 = 1 + (align 3) + 4 + 24 = 32, 由于32刚好是8的倍数,所以末尾无需额外填充,最后这个结构体的大小为32字节。
案例二
|
|
复制
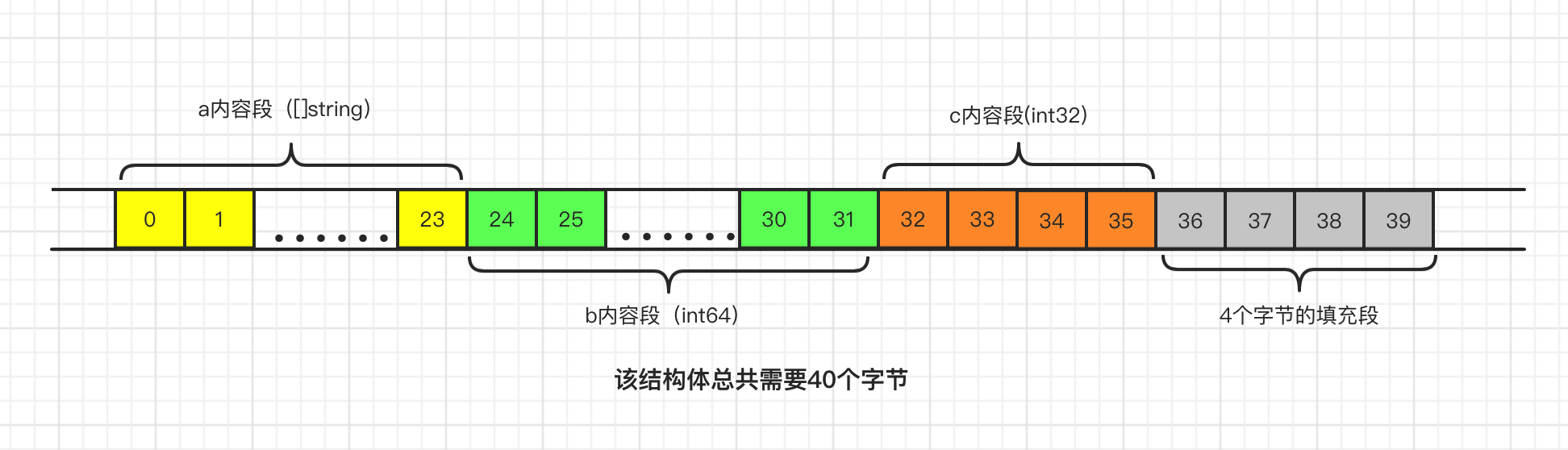 image.png
image.png
TestStruct2 内存占用大小分析:最大对齐边界为8字节,总体字节数 = 24(a) + 8(b) + 4(c) + 4(填充) = 40, 由于40刚好是8的倍数,所以c字段填充完后无需额外填充了。
案例三
|
|
复制
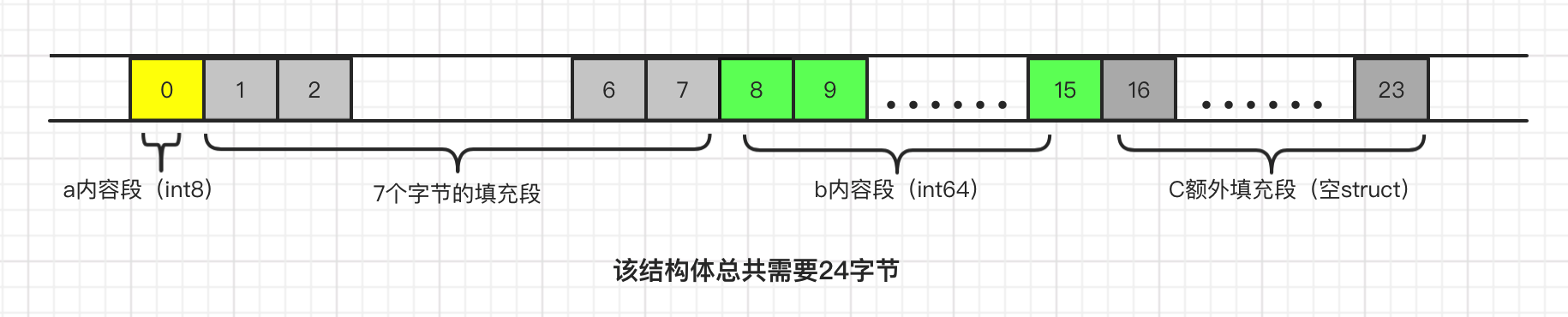 image.png
image.png
TestStruct3 内存占用大小分析:最大对齐边界为8字节,总体字节数 = 1(a)+ 7(填充) + 8(b) + 8(c填充)=24, 空结构体理论上不占字节,但是如果在另一个结构体尾部则需要进行额外字节对齐 。
案例四
|
|
复制
 image.png
image.png
TestStruct4 内存占用大小分析:最大对齐边界为4字节,总体字节数 = 0(a)+ 1(b)+ 7(填充) + 4(c) = 8。
(3) 测试验证
执行以下代码(环境是64位机器字长的)就可以看到我们之前案例中分析的结果。
|
|
输出为:
|
|
文章作者 cold-bin
上次更新 2022-07-17