Redis基础

文章目录
1.初识Redis
Redis是一种键值型的NoSql数据库,这里有两个关键字:
-
键值型
-
NoSql
其中键值型,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符串、数值、甚至json:

而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
1.1.认识NoSQL
NoSql可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
1.1.1.结构化与非结构化
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,插入的数据必须遵守这些约束:

而NoSql则对数据库格式没有严格约束,往往形式松散,自由。
可以是键值型:

也可以是文档型:

甚至可以是图格式:
1.1.2.关联和非关联
传统数据库的表与表之间往往存在关联,例如外键:

而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
|
|
此处要维护“张三”的订单与商品“荣耀”和“小米11”的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
1.1.3.查询方式
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。

1.1.4.事务
传统关系型数据库能满足事务ACID的原则。

而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
1.1.5.总结
除了上述四点以外,在存储方式、扩展性、查询性能上关系型与非关系型也都有着显著差异,总结如下:

- 存储方式
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
1.2.认识Redis
Redis诞生于2009年全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
作者:Antirez
Redis的官方网站地址:https://redis.io/
1.3.安装Redis
大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包。因此课程中我们会基于Linux系统来安装Redis.
此处选择的Linux版本为CentOS 7.
1.3.1.依赖库
Redis是基于C语言编写的,因此首先需要安装Redis所需要的gcc依赖:
|
|
1.3.2.上传安装包并解压
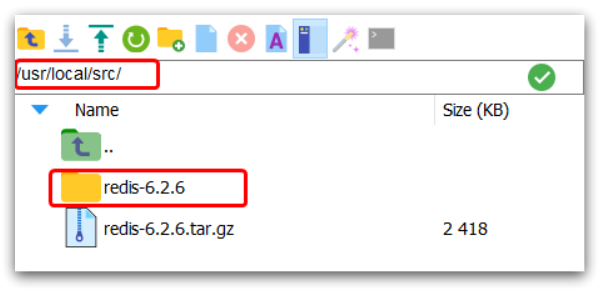
然后将课前资料提供的Redis安装包上传到虚拟机的任意目录:

例如,我放到了/usr/local/src 目录:

解压缩:
|
|
解压后:
进入redis目录:
|
|
运行编译命令:
|
|
如果没有出错,应该就安装成功了。
默认的安装路径是在 /usr/local/bin目录下:
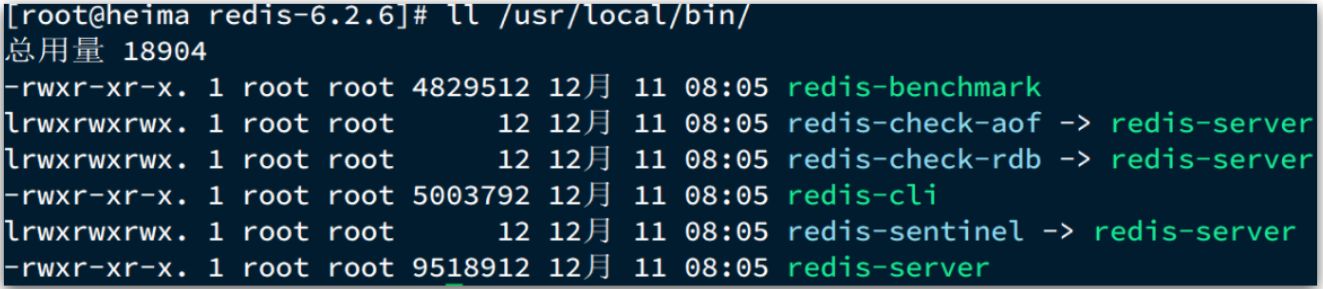
该目录已经默认配置到环境变量,因此可以在任意目录下运行这些命令。其中:
- redis-cli:是redis提供的命令行客户端
- redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本
1.3.3.启动
redis的启动方式有很多种,例如:
- 默认启动
- 指定配置启动
- 开机自启
1.3.4.默认启动
安装完成后,在任意目录输入redis-server命令即可启动Redis:
|
|
如图:

这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
1.3.5.指定配置启动
如果要让Redis以后台方式启动,则必须修改Redis配置文件,就在我们之前解压的redis安装包下(/usr/local/src/redis-6.2.6),名字叫redis.conf:
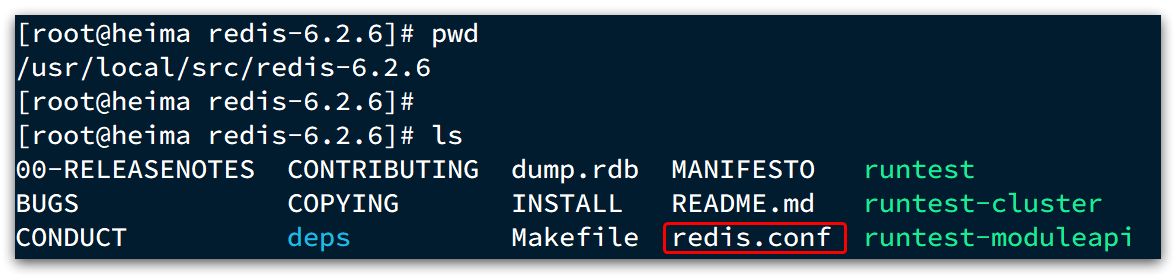
我们先将这个配置文件备份一份:
|
|
然后修改redis.conf文件中的一些配置:
|
|
Redis的其它常见配置:
|
|
启动Redis:
|
|
停止服务:
|
|
1.3.6.开机自启
我们也可以通过配置来实现开机自启。
首先,新建一个系统服务文件:
|
|
内容如下:
|
|
然后重载系统服务:
|
|
现在,我们可以用下面这组命令来操作redis了:
|
|
执行下面的命令,可以让redis开机自启:
|
|
1.4.Redis桌面客户端
安装完成Redis,我们就可以操作Redis,实现数据的CRUD了。这需要用到Redis客户端,包括:
- 命令行客户端
- 图形化桌面客户端
- 编程客户端
1.4.1.Redis命令行客户端
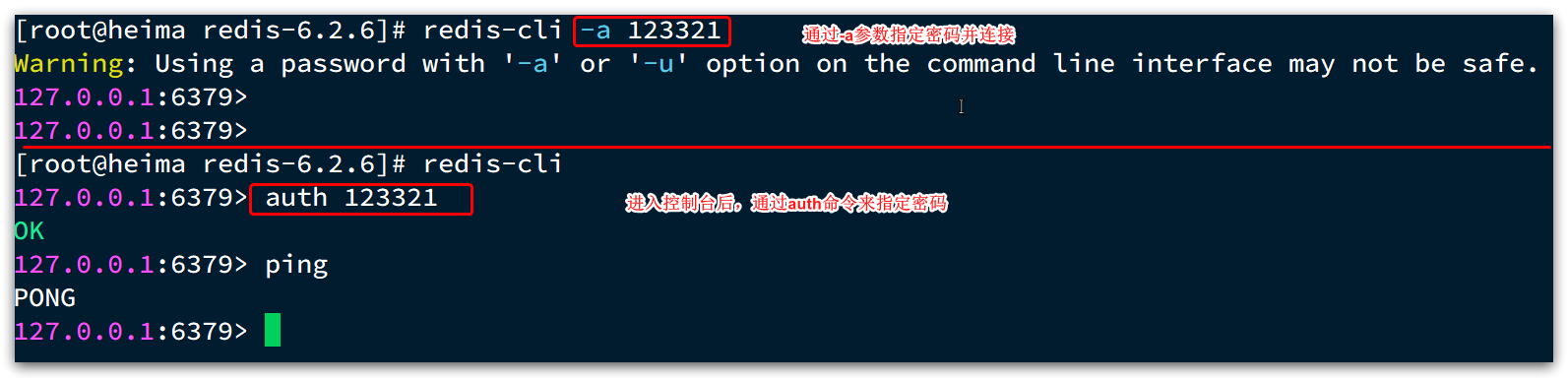
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
|
|
其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123321:指定redis的访问密码
其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong
不指定commond时,会进入redis-cli的交互控制台:
1.4.2.图形化桌面客户端
GitHub上的大神编写了Redis的图形化桌面客户端,地址:https://github.com/uglide/RedisDesktopManager
不过该仓库提供的是RedisDesktopManager的源码,并未提供windows安装包。
在下面这个仓库可以找到安装包:https://github.com/lework/RedisDesktopManager-Windows/releases
1.4.3.安装
在课前资料中可以找到Redis的图形化桌面客户端:

解压缩后,运行安装程序即可安装:

安装完成后,在安装目录下找到rdm.exe文件:

双击即可运行:

1.4.4.建立连接
点击左上角的连接到Redis服务器按钮:
在弹出的窗口中填写Redis服务信息:

点击确定后,在左侧菜单会出现这个链接:

点击即可建立连接了。

Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库:
|
|
2.Redis常见命令与数据类型
Redis是典型的key-value数据库,key一般是字符串,而value包含很多不同的数据类型:

Redis为了方便我们学习,将操作不同数据类型的命令也做了分组,在官网( https://redis.io/commands )可以查看到不同的命令:

不同类型的命令称为一个group,我们也可以通过help命令来查看各种不同group的命令:

接下来,我们就学习常见的五种基本数据类型的相关命令。
2.1.Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
-
KEYS:查看符合模板的所有key
-
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]:
增量迭代遍历,相较于KEYS命令更友好,因为KEYS会返回所有键数据,如果数据量太大会造成比较大的延时
-
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC|DESC] [ALPHA] [STORE destination]:
返回或存储 list, set 或sorted set 中的元素。默认是按照数值排序的,并且按照两个元素的双精度浮点数类型值进行比较。
-
DEL:删除一个指定的key
-
EXISTS:判断key是否存在
-
EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
-
TTL:查看一个KEY的剩余有效期
通过help [command] 可以查看一个命令的具体用法,例如:
|
|
2.1.1.Key结构
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,那就会冲突了,该怎么办?
我们可以通过给key添加前缀加以区分,不过这个前缀不是随便加的,有一定的规范:
Redis的key允许有多个单词形成层级结构,多个单词之间用’:‘隔开,格式如下:
|
|
这个格式并非固定,也可以根据自己的需求来删除或添加词条。这样以来,我们就可以把不同类型的数据区分开了。从而避免了key的冲突问题。
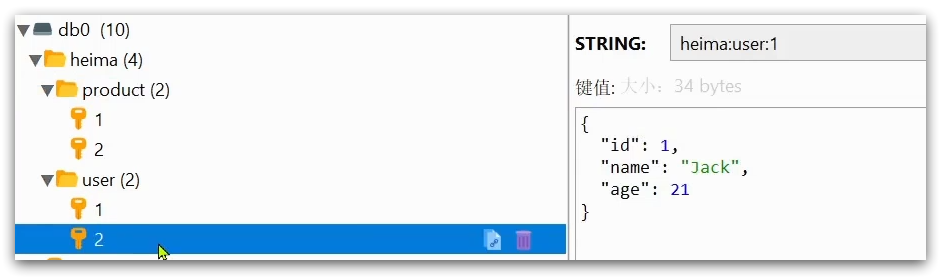
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
-
user相关的key:heima:user:1
-
product相关的key:heima:product:1
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {“id”:1, “name”: “Jack”, “age”: 21} |
| heima:product:1 | {“id”:1, “name”: “小米11”, “price”: 4999} |
并且,在Redis的桌面客户端中,还会以相同前缀作为层级结构,让数据看起来层次分明,关系清晰:
2.2.String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m.

2.2.1.String的常见命令
String的常见命令有:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
2.3.Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:

Hash的常见命令有:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HDEL:删除一个或多个哈希表字段
- HEXISTS:查看哈希表 key 中,指定的字段是否存在
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HSCAN:迭代哈希表中的键值对(当然,一般hash不会存有巨量键值对,所以,HSCAN的意义不是很大)
- HKEYS:获取一个hash类型的key中的所有的field
- HLEN:获取哈希表中字段的数量
- HSTRLEN:返回哈希表 key 中, 与给定域 field 相关联的值的字符串长度
- HVALS:获取哈希表中所有值
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HINCRBYFLOAT:为哈希表 key 中的指定字段的浮点数值加上增量 increment
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
2.4.List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
List的常见命令有:
- LINDEX: 返回列表 key 里索引 index 位置存储的元素。(支持负数倒序索引,-1表示倒数第一个,-2表示倒数第二个)
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil. 阻塞版本操作
2.5.Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
-
无序
-
元素不可重复
-
查找快
-
支持交集、并集、差集等功能。这些功能很契合一些业务。
Set的常见命令有:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
- SINTER key1 key2 … :求key1与key2的交集
- SDIFF:返回第一个集合和其他集合的差集
- SDIFFSTORE:SDIFF过后再存储到destination
- SINTER:返回所有给定集合的成员交集。后缀-store就类似上面
- SUINON:返回所有给定集合的并集。后缀-store就类似上面
- SSCAN:迭代集合中的元素。当需要取出集合数据量巨大时,也可以考虑使用SSCAN迭代读取
例如两个集合:s1和s2:
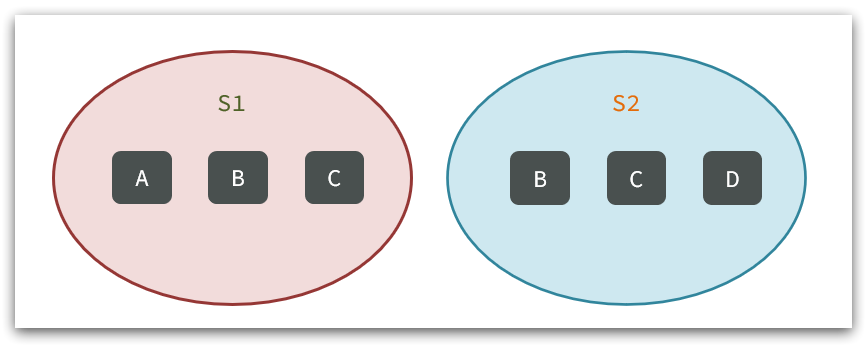
求交集:SINTER s1 s2
求s1与s2的不同:SDIFF s1 s2

练习:
- 将下列数据用Redis的Set集合来存储:
- 张三的好友有:李四、王五、赵六
- 李四的好友有:王五、麻子、二狗
- 利用Set的命令实现下列功能:
- 计算张三的好友有几人
- 计算张三和李四有哪些共同好友
- 查询哪些人是张三的好友却不是李四的好友
- 查询张三和李四的好友总共有哪些人
- 判断李四是否是张三的好友
- 判断张三是否是李四的好友
- 将李四从张三的好友列表中移除
2.6.SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
-
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member …]:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
ZADD 支持参数,参数位于 key 名字和第一个 score 参数之间:
- XX: 仅更新存在的成员,不添加新成员。
- NX: 不更新存在的成员。只添加新成员。
- LT: 更新新的分值比当前分值小的成员,不存在则新增。
- GT: 更新新的分值比当前分值大的成员,不存在则新增。
- CH: 返回变更成员的数量。变更的成员是指 新增成员 和 score值更新的成员,命令指明的和之前score值相同的成员不计在内。 注意: 在通常情况下,ZADD返回值只计算新添加成员的数量。
- INCR: ZADD 使用该参数与 ZINCRBY 功能一样。一次只能操作一个score-element对。
注意: GT, LT 和 NX 三者互斥不能同时使用。
-
ZREM key member:删除sorted set中的一个指定元素
-
ZSCORE key member : 获取sorted set中的指定元素的score值
-
ZRANK key member:获取sorted set 中的指定元素的排名
-
ZCARD key:获取sorted set中的元素个数
-
ZCOUNT key min max:统计score值在给定范围内的所有元素的个数。注意时间复杂度达到了O(logN)
-
ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
-
ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
-
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
-
ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
-
升序获取sorted set 中的指定元素的排名:ZRANK key member
-
降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
练习题:
将班级的下列学生得分存入Redis的SortedSet中:
Jack 85, Lucy 89, Rose 82, Tom 95, Jerry 78, Amy 92, Miles 76
并实现下列功能:
- 删除Tom同学
- 获取Amy同学的分数
- 获取Rose同学的排名
- 查询80分以下有几个学生
- 给Amy同学加2分
- 查出成绩前3名的同学
- 查出成绩80分以下的所有同学
2.7.HyperLogLog类型
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 264 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
常用命令:
- PFADD key element [element …]:添加指定元素到 HyperLogLog 中。
- PFCOUNT key [key …]:返回给定 HyperLogLog 的基数估算值。
- PFMERGE destkey sourcekey [sourcekey …]:将多个 HyperLogLog 合并为一个 HyperLogLog(并集)
2.8.GEO类型
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
-
GEOADD key longitude latitude member [longitude latitude member …]:添加地理位置的坐标。
-
GEOPOS key member [member …]:获取地理位置的坐标。
-
GEODIST key member1 member2 [m|km|ft|mi]:计算两个位置之间的距离。
最后一个距离单位参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
-
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺
- WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- WITHCOORD: 将位置元素的经度和维度也一并返回。
- WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
- COUNT 限定返回的记录数。
- ASC: 查找结果根据距离从近到远排序。
- DESC: 查找结果根据从远到近排序。
-
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
- WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- WITHCOORD: 将位置元素的经度和维度也一并返回。
- WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
- COUNT 限定返回的记录数。
- ASC: 查找结果根据距离从近到远排序。
- DESC: 查找结果根据从远到近排序。
-
GEOHASH key member [member …]:返回一个或多个位置对象的 geohash 值。
2.9.Stream类型
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Stream 实际上是一个具有消息发布/订阅功能的组件,也就常说的消息队列。其实这种类似于 broker/consumer(生产者/消费者)的数据结构很常见,比如 RabbitMQ 消息中间件、Celery 消息中间件,以及 Kafka 分布式消息系统等,而 Redis Stream 正是借鉴了 Kafaka 系统。
1) 优点
Strean 除了拥有很高的性能和内存利用率外, 它最大的特点就是提供了消息的持久化存储,以及主从复制功能,从而解决了网络断开、Redis 宕机情况下,消息丢失的问题,即便是重启 Redis,存储的内容也会存在。
2) 流程
Stream 消息队列主要由四部分组成,分别是:消息本身、生产者、消费者和消费组,对于前述三者很好理解,下面了解什么是消费组。
一个 Stream 队列可以拥有多个消费组,每个消费组中又包含了多个消费者,组内消费者之间存在竞争关系。当某个消费者消费了一条消息时,同组消费者,都不会再次消费这条消息。被消费的消息 ID 会被放入等待处理的 Pending_ids 中。每消费完一条信息,消费组的游标就会向前移动一位,组内消费者就继续去争抢下消息。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
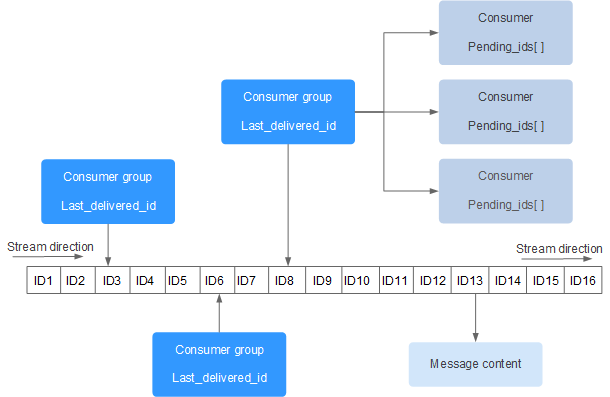
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
上图解析:
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id ,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
2.10.bitmap位图操作
在平时开发过程中,经常会有一些 bool 类型数据需要存取。比如记录用户一年内签到的次数,签了是 1,没签是 0。如果使用 key-value 来存储,那么每个用户都要记录 365 次,当用户成百上亿时,需要的存储空间将非常巨大。为了解决这个问题,Redis 提供了位图结构。
位图(bitmap)同样属于 string 数据类型。Redis 中一个字符串类型的值最多能存储 512 MB 的内容,每个字符串由多个字节组成,每个字节又由 8 个 Bit 位组成。位图结构正是使用“位”来实现存储的,它通过将比特位设置为 0 或 1来达到数据存取的目的,这大大增加了 value 存储数量,它存储上限为2^32 。
位图本质上就是一个普通的字节串,也就是 bytes 数组。您可以使用getbit/setbit命令来处理这个位数组,位图的结构如下所示:

位图适用于一些特定的应用场景,比如用户签到次数、或者登录次数等。上图是表示一位用户 10 天内来网站的签到次数,1 代表签到,0 代表未签到,这样可以很轻松地统计出用户的活跃程度。相比于直接使用字符串而言,位图中的每一条记录仅占用一个 bit 位,从而大大降低了内存空间使用率。
Redis 官方也做了一个实验,他们模拟了一个拥有 1 亿 2 千 8 百万用户的系统,然后使用 Redis 的位图来统计“日均用户数量”,最终所用时间的约为 50ms,且仅仅占用 16 MB内存。
2.10.1.位图应用原理
某网站要统计一个用户一年的签到记录,若用 sring 类型存储,则需要 365 个键值对。若使用位图存储,用户签到就存 1,否则存 0。最后会生成 11010101… 这样的存储结果,其中每天的记录只占一位,一年就是 365 位,约为 46 个字节。如果只想统计用户签到的天数,那么统计 1 的个数即可。
位图操作的优势,相比于字符串而言,它不仅效率高,而且还非常的节省空间。
Redis 的位数组是自动扩展的,如果设置了某个偏移位置超出了现有的内容范围,位数组就会自动扩充。
下面设置一个名为 a 的 key,我们对这个 key 进行位图操作,使得 a 的对应的 value 变为“he”。
首先我们分别获取字符“h”和字符“e”的八位二进制码,如下所示:
|
|
接下来,只要对需值为 1 的位进行操作即可。如下图所示:
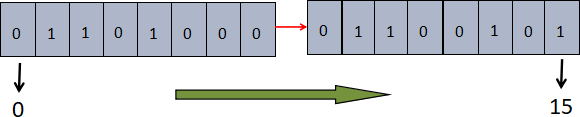
把 h 和 e 的二进制码连接在一起,第一位的下标是 0,依次递增至 15,然后将数字为 1 的位置标记出来,得到 1/2/4/9/10/13/15,我们把这组数字称为位的“偏置数”,最后按照上述偏置数对字符 a 进行如下位图操作。注意,key 的初始二进制位全部为 0。
|
|
从上述示例可以得出,位图操作会自动对 key 进行扩容。
如果对应位的字节是不可以被打印的,那么 Redis 会以该字符的十六进制数来表示它,如下所示:
|
|
常用命令:
- SETBIT key offset value:用来设置或者清除某一位上的值,其返回值是原来位上存储的值。key 在初始状态下所有的位都为 0
- GETBIT key offset:用来获取某一位上的值。当偏移量 offset 比字符串的长度大,或者当 key 不存在时,返回 0。
- BITCOUNT key [start end]:统计指定位区间上,值为 1 的个数。通过指定的 start 和 end 参数,可以让计数只在特定的字节上进行。start 和 end 参数和 GETRANGE 命令的参数类似,都可以使用负数,比如 -1 表示倒数第一个位, -2 表示倒数第二个位。
3.Redis的Java客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:
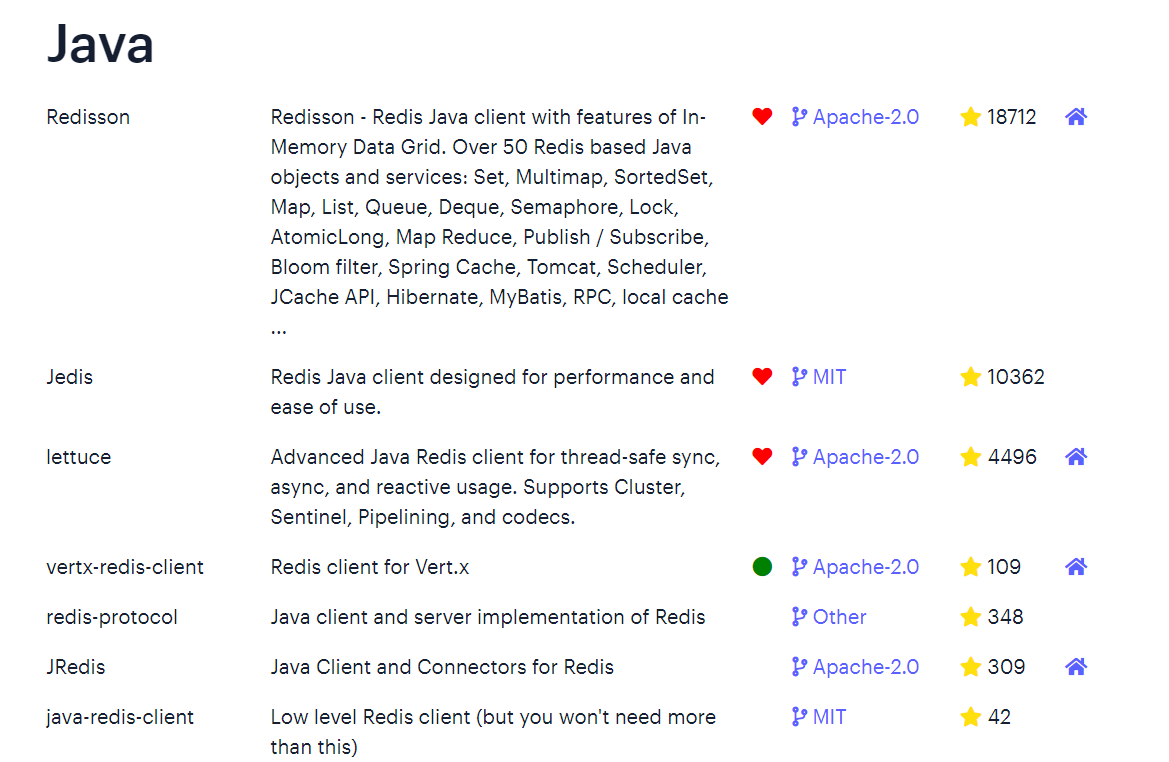
标记为*的就是推荐使用的java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
3.1.Jedis客户端
Jedis的官网地址: https://github.com/redis/jedis
3.1.1.快速入门
我们先来个快速入门:
1)引入依赖:
|
|
2)建立连接
新建一个单元测试类,内容如下:
|
|
3)测试:
|
|
4)释放资源
|
|
3.1.2.连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
|
|
3.2.SpringDataRedis客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

3.2.1.快速入门
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简单。
首先,新建一个maven项目,然后按照下面步骤执行:
1)引入依赖
|
|
2)配置Redis
|
|
3)注入RedisTemplate
因为有了SpringBoot的自动装配,我们可以拿来就用:
|
|
4)编写测试
|
|
3.2.2.自定义序列化
RedisTemplate可以接收任意Object作为值写入Redis:

只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
|
|
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:

整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
3.2.3.StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。

因为存入和读取时的序列化及反序列化都是我们自己实现的,SpringDataRedis就不会将class信息写入Redis了。
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。

省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
|
|
文章作者 cold-bin
上次更新 2023-01-08